动态类型语言 VS 静态类型语言
一. 运行期动态修改类型结构动态编程语言是高级编程语言的一个类别,在计算机科学领域已被广泛应用。它是一类在运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。动态语言目前非常具有活力。众所周知的ECMAScript(JavaScript)便是一个动态语言,除此之外如PHP、Ruby、Python等也都属于动态语言,而C、C++、Java等语言则不属于动态语言。
例如下列 Python 代码:
1234567891011121314class Student(object): def __init__(self, name): self.name = nameif __name__ == '__main__': stu = Student("张三") stu.age = 18 # 运行时,给stu对象新增了一个age属性,但是在class声明时未声明该属性 def to_string(self): return f"Student ...

Arthas源码分析
一. 前言Arthas 相信大家已经不陌生了,肯定用过太多次了,平时说到 Arthas 的时候都知道是基于Java Agent的,那么他具体是怎么实现呢,今天就一起来看看。
首先 Arthas 是在 GitHub 开源的,我们可以直接去 GitHub 上获取源码:Arthas。
本文基于 Arthas 3.6.7 版本源码进行分析,具体源码注释可参考:bigcoder84/arthas
二. arthas源码调试在阅读源码的时候少不了需要对源码进行DEBUG,Arthas Debug 需要借助 IDEA 的远程Debug功能,具体可参考:
Debug Arthas In IDEA · Issue #222 · alibaba/arthas (github.com)
第一步:编写测试类
1234567891011121314public class Main { public static void main(String[] args) throws InterruptedException { int i = 0; ...

Java应用的优雅停机
一. 优雅停机的概念优雅停机一直是一个非常严谨的话题,但由于其仅仅存在于重启、下线这样的部署阶段,导致很多人忽视了它的重要性,但没有它,你永远不能得到一个完整的应用生命周期,永远会对系统的健壮性持怀疑态度。
同时,优雅停机又是一个庞大的话题
操作系统层面,提供了 kill -9 (SIGKILL)和 kill -15(SIGTERM) 两种停机策略
语言层面,Java 应用有 JVM shutdown hook 这样的概念
框架层面,Spring Boot 提供了 actuator 的下线 endpoint,提供了 ContextClosedEvent 事件
容器层面,Docker :当执行 docker stop 命令时,容器内的进程会收到 SIGTERM 信号,那么 Docker Daemon 会在 10s 后,发出 SIGKILL 信号;K8S 在管理容器生命周期阶段中提供了 prestop 钩子方法。
应用架构层面,不同架构存在不同的部署方案。单体式应用中,一般依靠 nginx 这样的负载均衡组件进行手动切流,逐步部署集群;微服务架构中,各个节点之间有复杂的调用关系,上述这种 ...
Dubbo SPI扩展机制源码详解(基于2.7.10)
一. 概述本文主要分享 Dubbo 的拓展机制 SPI。
想要理解 Dubbo ,理解 Dubbo SPI 是非常必须的。在 Dubbo 中,提供了大量的拓展点,基于 Dubbo SPI 机制加载
Dubbo SPI官方文档:Dubbo SPI 概述 | Apache Dubbo
本文基于 Dubbo 2.7.10 版本源码
二. Dubbo SPI特性在看具体的 Dubbo SPI 实现之前,我们先理解 Dubbo SPI 产生的背景:
Dubbo 的扩展点加载从 JDK 标准的 SPI (Service Provider Interface) 扩展点发现机制加强而来。
Dubbo 改进了 JDK 标准的 SPI 的以下问题:
JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
如果扩展点加载失败,连扩展点的名称都拿不到了。比如:JDK 标准的 ScriptEngine,通过 getName() 获取脚本类型的名称,但如果 RubyScriptEngine 因为所依赖的 jruby.jar 不存在,导致 Ruby ...

安利一个好用的IDEA插件 object-helper-plugin
一. 插件背景object-helper 插件是一个日常开发工具集插件,提供丰富的功能,最开始是基于 GenerateO2O 插件开发而来,它提供了对象之间值拷贝代码自动生成的能力,就像这样:
因为它很早之前就停止维护了,新版本IDEA无法使用该插件,所以自己参考它的交互模式,基于新版本API开发了初版 object-helper-plugin插件,再次感谢 GenerateO2O 的作者。
根据日常开发中的痛点,object-helper-plugin 插件不断迭代,提供着我们的开发效率。
欢迎大家在 Issues 中提出宝贵意见,也可以联系我成为一名插件开发者,共同完善插件的功能。
object-helper插件源码:object-helper-plugin
二. 插件下载方式一:
官网下载:ObjectHelper - IntelliJ IDEs Plugin | Marketplace (jetbrains.com)
方式二:
插件市场搜索 “ObjectHelper”
方式三:
Github下载最新安装包,拖入IDEA即可:object-helper-plugin
二. ...

详解 XSS 攻击原理
跨站脚本攻击(Cross Site Scripting)本来的缩写为CSS,为了与层叠样式表(Cascading Style Sheets,CSS)的缩写进行区分,将跨站脚本攻击缩写为XSS。因此XSS是跨站脚本的意思。
XSS跨站脚本攻击(Cross Site Scripting)的本质是攻击者在web页面插入恶意的script代码(这个代码可以是JS脚本、CSS样式或者其他意料之外的代码),当用户浏览该页面之时,嵌入其中的script代码会被执行,从而达到恶意攻击用户的目的。比如读取cookie,token或者网站其他敏感的网站信息,对用户进行钓鱼欺诈等。比较经典的事故有:
一. 存储型XSS攻击1.1 攻击原理存储型XSS又称为持久型XSS,是指:攻击者将XSS代码发送给了后端,而后端没有对这些代码做处理直接存储在数据库中。当用户访问网站时,又直接从数据库调用出来传给前端,前端解析XSS代码就造成了XSS攻击。
存储型 XSS 的攻击步骤:
攻击者将恶意代码提交到目标网站的数据库中。
用户打开目标网站时,网站服务端将恶意代码从数据库取出,拼接在 HTML 中返回给浏览器。
用户 ...

计算机算法的本质(转)
最近忽然想起自己很久没有刷过算法题了,在 Leetcode 上捡了几题刷了一下,发现手确实生了,看到了 labuladong 大佬对数据结构和算法的理解比较深入,故做此记录。
如果要让我⼀句话总结,我想说算法的本质就是「穷举」。
这么说肯定有人要反驳了,真的所有算法问题的本质都是穷举吗?没有例外吗?
例外肯定是有的,比如前几天我还发了 一行代码就能解决的算法题,这些题目类似脑筋急转弯,都是通过观察,发现规律,然后找到最优解法,不过这类算法问题较少,不必特别纠结。再比如,密码学算法、机器学习算法,它们的本质确实不是穷举,而是数学原理的编程实现,所以这类算法的本质是数学,不在我们所探讨的「数据结构和算法」的范畴之内。
顺便强调下,「算法工程师」做的这个「算法」,和「数据结构与算法」中的这个「算法」完全是两码事, 免得⼀些初学同学误解。
对前者来说,重点在数学建模和调参经验,计算机真就只是拿来做计算的工具而已;而后者的重点是计算机思维,需要你能够站在计算机的视角,抽象、化简实际问题,然后用合理的数据结构去解决问题。
所以,你千万别以为学好了数据结构和算法就能去做算法工程师了,也不要以为只 ...
超大规模流量热点key读问题解决思路
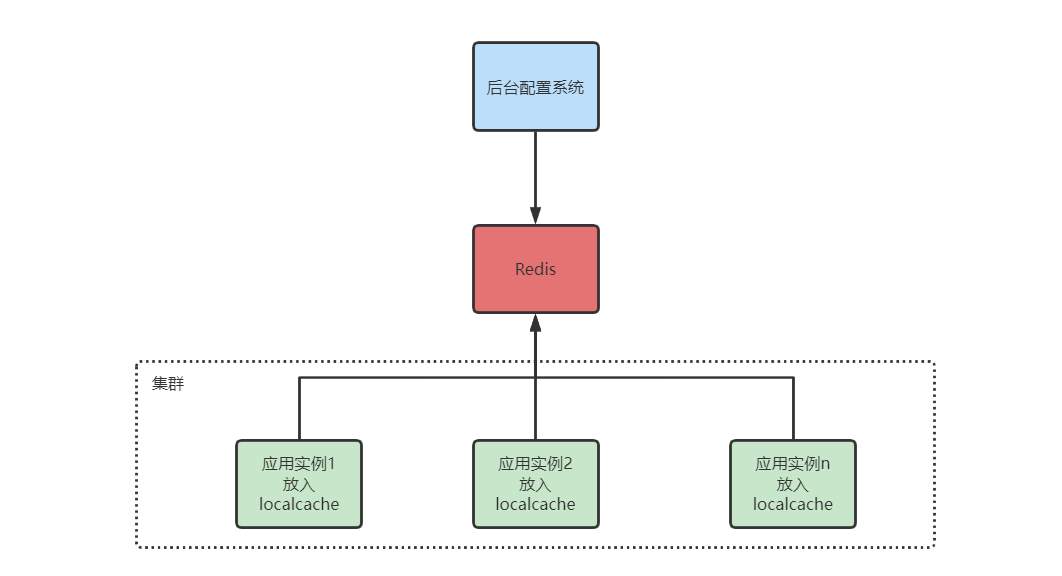
在程序中使用缓存技术,不仅能够提升系统整体的响应速度,还能在一定程度上有效降低关系数据库的负载压力。尽管对 Redis 进行 Cluster后可以理论上认为容量是可以无限延伸的,并且数据的读/写操作经过了水平化处理,不同的key均会落到不同的缓存节点上,以此避免所有的用户流量都集中落到同一个缓存节点上。但是对于限时抢购场景下的热卖商品来说,由于单价比平时更给力、更具吸引力,那么自然会比平时吸引更大的流量进来,这时同一个key必然会落到同一个缓存节点上,因此分布式缓存在这种情况下一定会出现单点瓶颈。
笔者举一个贴近生活的例子,某明星出轨的消息很容易引爆流量,有可能随着事件的发酵会在接下来的一周内稳坐各大新闻版面头条。单从技术细节上来分析,假设这条消息存储在分布式缓存中,但由于消息是缓存在固定的 Slot 上的,尽管缓存系统单点支撑 10w/s 的 QPS 没有任何压力,但是在短短几分钟内,光是用户留言就达到了上百万条,更别说是阅读这条消息时所产生的流量,因此分布式缓存的单点容量容易瞬间被撑爆,导致资源连接耗尽。为了解决分布式缓存存在的单点瓶颈,我们通常可以通过以下两种 ...

详解Spring循环依赖
一. 从类加载说起Java中的类加载器负载加载来自文件系统、网络或者其他来源的类文件。jvm的类加载器默认使用的是双亲委派模式。三种默认的类加载器Bootstrap ClassLoader、Extension ClassLoader和System ClassLoader(Application ClassLoader)每一个中类加载器都确定了从哪一些位置加载文件。于此同时我们也可以通过继承 java.lang.classloader 实现自己的类加载器。
Bootstrap ClassLoader:负责加载JDK自带的rt.jar包中的类文件,是所有类加载的父类
Extension ClassLoader:负责加载java的扩展类库从jre/lib/ect目录或者java.ext.dirs系统属性指定的目录下加载类,是System ClassLoader的父类加载器
System ClassLoader:负责从classpath环境变量中加载类文件
1.1 双亲委派当一个类加载器收到类加载任务时,会先交给自己的父加载器去完成,因此最终加载任务都会传递到最顶层 ...
详解Spring SPI机制
一. 从类加载说起Java中的类加载器负载加载来自文件系统、网络或者其他来源的类文件。jvm的类加载器默认使用的是双亲委派模式。三种默认的类加载器Bootstrap ClassLoader、Extension ClassLoader和System ClassLoader(Application ClassLoader)每一个中类加载器都确定了从哪一些位置加载文件。于此同时我们也可以通过继承 java.lang.classloader 实现自己的类加载器。
Bootstrap ClassLoader:负责加载JDK自带的rt.jar包中的类文件,是所有类加载的父类
Extension ClassLoader:负责加载java的扩展类库从jre/lib/ect目录或者java.ext.dirs系统属性指定的目录下加载类,是System ClassLoader的父类加载器
System ClassLoader:负责从classpath环境变量中加载类文件
1.1 双亲委派当一个类加载器收到类加载任务时,会先交给自己的父加载器去完成,因此最终加载任务都会传递到最顶层 ...