LLM 只会生成文本?用 ReAct 模式手搓一个简易 Claude Code Agent
在大语言模型(LLM)技术飞速发展的今天,单纯的文本生成能力已无法满足复杂任务的需求。Agent 作为一种能够自主决策、规划和执行任务的智能体,正在成为 LLM 落地应用的关键载体。而 ReAct 模式作为 Agent 领域的重要范式,通过 “思考 - 行动 - 观察” 的循环机制,极大地提升了 Agent 的逻辑性和任务解决能力。本文将从基础概念出发,逐步深入 ReAct 模式 Agent 的实现原理,并通过网页端模拟和代码实践,带大家从零构建一个最简单的 ReAct 模式 Agent。
一. 什么是 Agent
在人工智能领域,Agent(智能体) 是指能够自主感知环境、做出决策并执行动作,以实现特定目标的实体。它并非单一的算法或模型,而是一个集成了 “感知 - 决策 - 执行” 能力的闭环系统。结合 LLM 技术的 Agent,核心特征可概括为以下三点:
自主性(Autonomy):无需人类持续干预,能根据任务目标自主规划步骤。例如,当用户提出 “整理近 3 个月的销售数据并生成可视化报告” 时,Agent 可自主决定 “获取数据→清洗数据→分析数据→生成图表” 的流程,而非依赖人类逐步指导。
交互性(Interactivity):既能与外部环境(如数据库、API、工具)交互,也能与用户交互。例如,当 Agent 无法获取某份数据时,会主动询问用户 “请提供销售数据的存储路径”,或调用数据接口直接拉取数据。
目标导向性(Goal-Oriented):所有行为均围绕 “完成用户目标” 展开,具备动态调整策略的能力。若某一步骤失败(如数据接口超时),Agent 会尝试替代方案(如切换备用接口、手动上传数据),而非停滞不前。
简单来说,LLM 是 Agent 的 “大脑”(负责思考和决策),而 Agent 则是 LLM 的 “手脚”(负责与外部环境交互并执行任务)。
二. 什么是 ReAct Agent
ReAct(Reasoning and Acting) 的概念来自论文 《ReAct: Synergizing Reasoning and Acting in Language Models》,这篇论文提出了一种新的方法,通过结合语言模型中的推理(reasoning)和行动(acting)来解决多样化的语言推理和决策任务。ReAct 提供了一种更易于人类理解、诊断和控制的决策和推理过程。该论文虽然是2022年发布,但目前可能仍然是目前使用最为广泛的Agent模式。
它的典型流程如下图所示,可以用一个有趣的循环来描述:思考(Thought)→ 行动(Action)→ 观察(Observation),简称TAO循环。
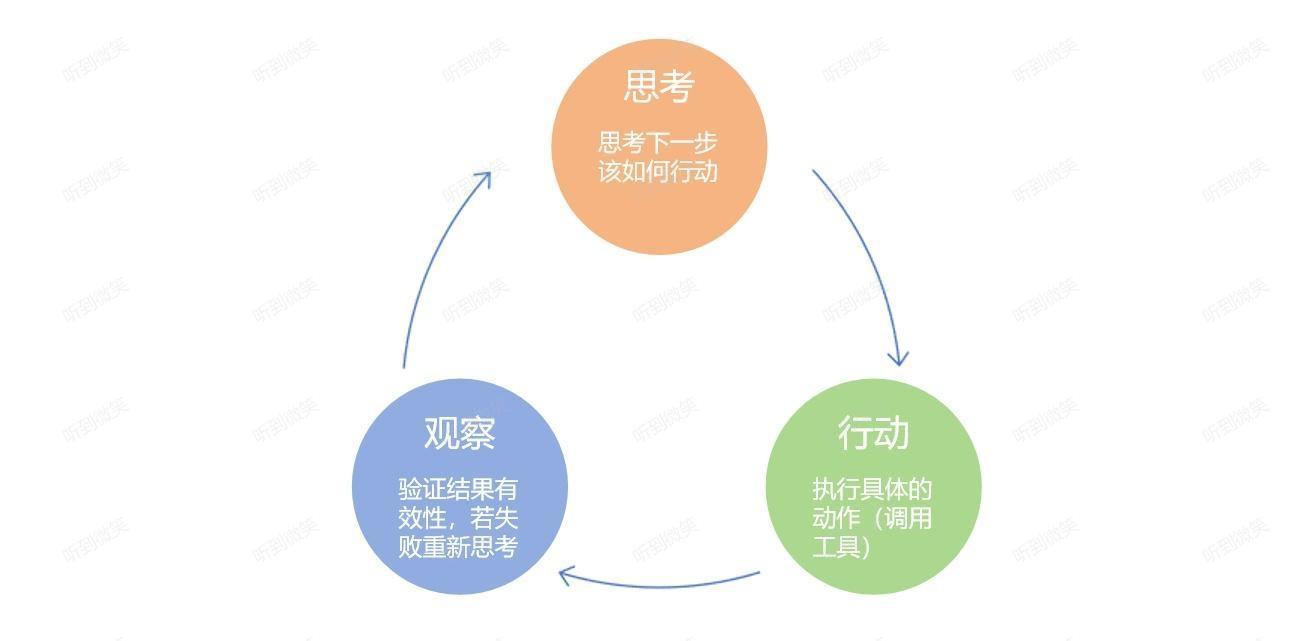
- 思考(Thought):AI Agent通过推理拆解任务,明确目标与路径。 例:用户询问“2025年斯诺克世锦赛决赛冠军是哪里人”的问题,LLM可能会拆分如下任务:
- 查询2025年斯诺克世锦赛冠军是谁
- 查询该人家乡在哪
- 行动(Action):调用工具执行具体操作(如计算、搜索API)。 技术细节:需预定义工具(如乘法计算工具)并通过Prompt模板引导LLM 调用。
- 观察(Observation):验证结果有效性,若失败则重新规划。 例:若搜索航班超预算,Agent自动调整“直飞→转机”策略。
三. ReAct模式实现原理
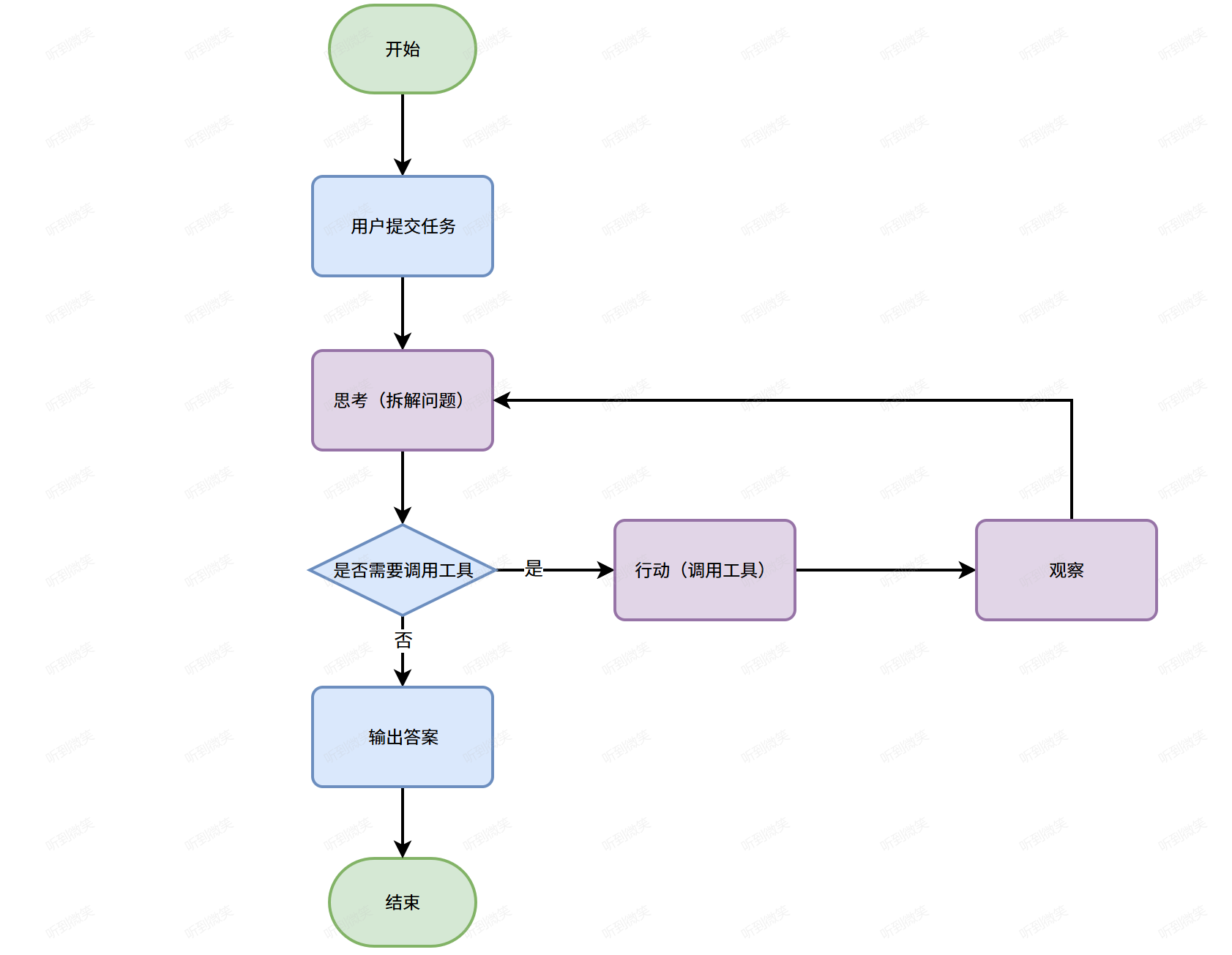
ReAct 模式 Agent 的实现本质是 “prompt 引导 LLM 生成决策→执行行动→获取反馈→更新 prompt→循环直至完成任务” 的闭环流程。其核心原理可拆解为以下 5 个步骤:
3.1 步骤1:构建初始 prompt—— 定义 ReAct 的 “规则框架”
首先需要设计结构化的 prompt,明确告知 LLM“如何思考、如何生成行动指令”。一个标准的 ReAct prompt 包含以下部分:
角色定义:明确 Agent 的身份(如 “数据查询助手”)和能力(如 “可调用搜索工具、表格生成工具”)。
任务目标:用户的具体需求(需动态传入)。
循环规则:告知 LLM 需交替生成 “Thought” 和 “Action”,直至任务完成(此时生成 “Final Answer”)。
格式约束:规定 “Thought” 和 “Action” 的输出格式(避免 LLM 生成杂乱内容),例如:
下方给出一个示例提示词:
你需要解决一个任务。为此,你需要将任务分解为多个步骤。对于每个步骤,首先使用
<thought>思考要做什么,然后使用<action>调用一个工具,工具的执行结果会通过<observation>返回给你。持续这个思考和行动的过程,直到你有足够的信息来提供<final_answer>。所有步骤请严格使用以下 XML 标签格式输出:
<task>: 用户提出的任务<thought>: 思考<action>: 采取的工具操作<observation>: 工具或环境返回的结果<final_answer>: 最终答案示例1:
2
3
4
5
6
<thought>要完成创建文件并写入内容的任务,首先得用write_to_file工具,参数设置好文件名和内容。</thought>
<action>write_to_file("test.txt", "Hello, World!")</action>
<observation>写入成功</observation>
<thought>工具返回写入成功,说明文件创建和内容写入都完成了,现在可以给出最终答案。</thought>
<final_answer>已在当前目录下创建名为"test.txt"的文件,并成功写入内容"Hello, World!"。</final_answer>示例2:
2
3
4
5
6
7
8
9
<thought>这个任务分两步。第一步,找到番茄炒蛋的食谱。第二步,检查冰箱里是否有西红柿。我先用 find_recipe 工具。</thought>
<action>find_recipe(dish="番茄炒蛋")</action>
<observation>简单的番茄炒蛋食谱:将2个鸡蛋打散,2个番茄切块。热油,先炒鸡蛋,盛出。再热油,炒番茄至软烂,加入炒好的鸡蛋,加盐调味即可。</observation>
<thought>好的,我已经有食谱了。食谱需要西红柿。现在我需要用 check_fridge 工具看看冰箱里有没有西红柿。</thought>
<action>check_fridge(item="西红柿")</action>
<observation>冰箱检查结果:有3个西红柿。</observation>
<thought>我找到了食谱,并且确认了冰箱里有西红柿。可以回答问题了。</thought>
<final_answer>简单的番茄炒蛋食谱是:鸡蛋打散,番茄切块。先炒鸡蛋,再炒番茄,混合后加盐调味。冰箱里有3个西红柿。</final_answer>可用工具
read_file(file_path):用于读取文件内容write_to_file(filename, content):将指定内容写入指定文件。成功时返回 “写入成功”。run_terminal_command(command):用于执行终端命令注意事项
<task>标签由用户提供,请不要擅自生成。- 你每次回答都必须包括两个标签,第一个是
<thought>,第二个是<action>或<final_answer>- 输出
<action>后立即停止生成,等待真实的<observation>,擅自生成<observation>将导致错误- 如果
<action>中的某个工具参数有多行的话,请使用\n来表示,如:
环境信息
- 操作系统:Windows 11
- 当前目录:
E:\software-engineer\llm- 目录下文件列表:空
3.2 步骤2:LLM 生成 “思考 - 行动”
将初始 prompt 传入 LLM(如 DeepSeek、QWen、GPT-5、Claude),LLM 会根据 prompt 的规则,先生成 “Thought”(分析任务),再生成符合格式的 “Action”(行动指令)。
我们以 DeepSeek 为例,向其提交 “帮我用HTML实现一个贪吃蛇小游戏” 任务,由于 DeepSeek 网页端没有区分系统提示词和用户提示词,我们就将原本需要放在系统提示词中的初始规范,和需要提交的任务<task>帮我用HTML、CSS、js实现一个贪吃蛇小游戏</task> 一起提交给DeepSeek:
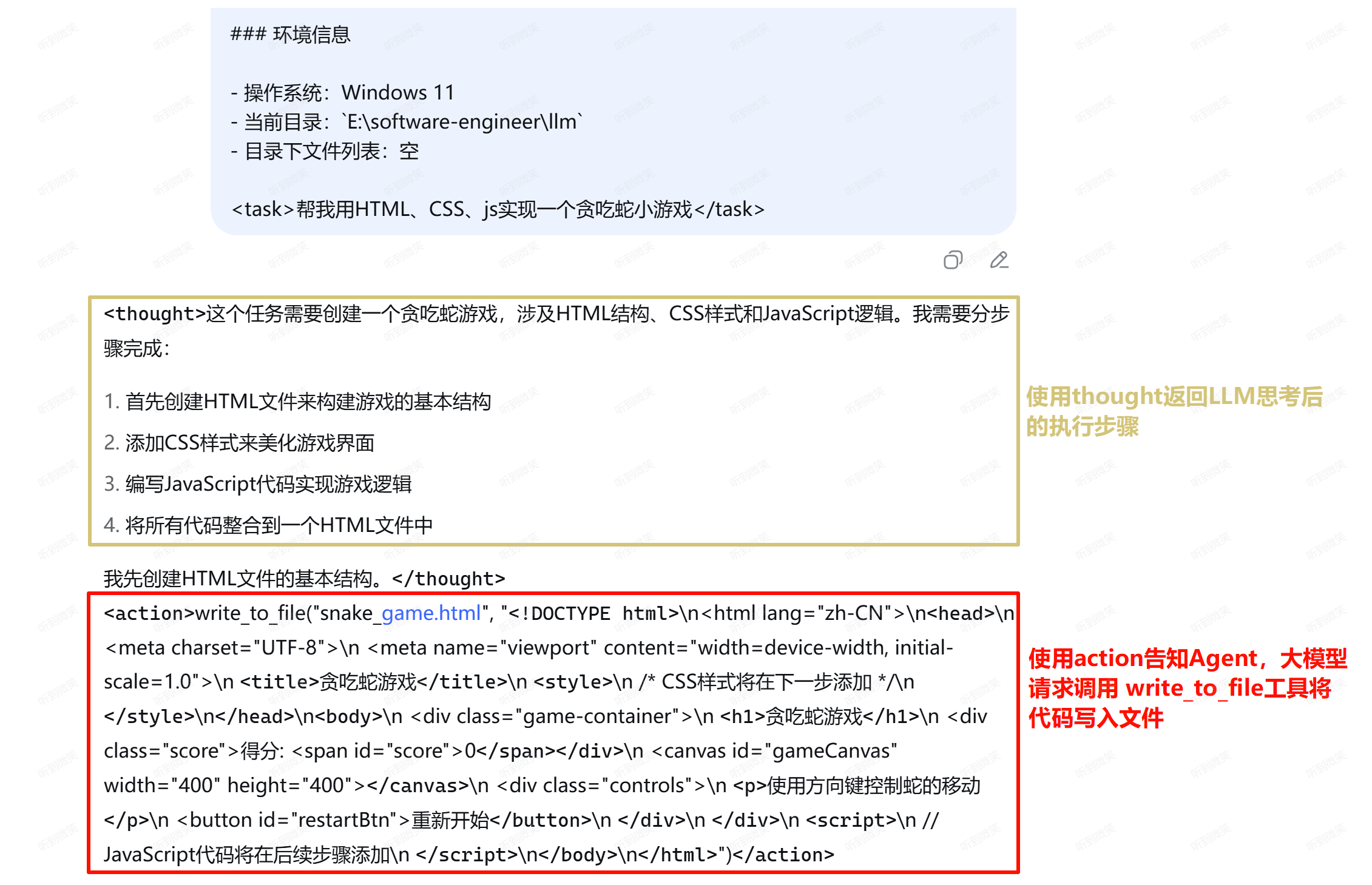
可以看到 DeepSeek 已经完全按照提示词要求的规范,将思考过程使用 thought 标签包裹,将请求调用工具的动作使用 action 包裹。
3.3 步骤3:执行行动并获取观察结果
此时Agent解析LLM返回的内容中包含 action 标签,证明Agent需要调用外部工具完成LLM的处理请求,执行完 action 标签的方法后,会获取到执行结果,Agent会将执行结果返回给LLM,我们Mock文件已经成功写入:
1 | <observation>写入成功</observation> |
3.4 步骤4:更新 prompt 并进入下一轮循环
将上一轮的 “Thought、Action、Observation” 追加到初始 prompt 中,形成 “历史上下文”,再传入 LLM。此时 LLM 会基于历史信息,判断是否需要继续行动:
- 若任务未完成,LLM 会生成新的 “Thought” 和 “Action”,例如:


3.5 步骤5:任务完成向用户输出结果
经过多轮的循环,任务最终完成,Agent检查到结果中存在 final_answer 标签后意识到任务已经完成,将标签内的内容输出给用户,最终结束该任务。

四. ReAct实践:使用 Python 实现简易版 Claude Code
4.1 核心代码
bigcoder84/claude-code-simple: 基于ReAct模式简易类似于Claude Code的Agent实现
1 | import ast |
4.2 提示词模板
1 | react_system_prompt_template = """ |
4.3 核心流程
sequenceDiagram
participant 用户
participant Agent主程序
participant 模型
participant 工具(函数)
autonumber
用户->>+Agent主程序: 写一个贪吃蛇
loop 重复 n 次
Agent主程序->>+模型: 请求模型
模型-->>-Agent主程序: Thought + Action
Agent主程序->>用户: 显示 Thought + Action
Agent主程序->>+工具(函数): 请求 Action 对应的工具
工具(函数)-->>-Agent主程序: 工具执行结果
Agent主程序->>用户: 显示工具执行结果
end
Agent主程序 ->> +模型: 请求模型
模型-->> -Agent主程序: Thought + Final Answer
Agent主程序 -->> -用户: 展示 Thought 和 Final Answer4.4 测试
执行如下命令:
1 | uv run agent.py snake |
然后输入任务描述后,agent就会按照ReAct模式不断请求LLM,直至完成任务:
五. LangChain Plan and Execute 模式
ReAct 通过 “思考 - 行动 - 观察” 的即时循环实现任务推进,每一步行动都依赖上一轮的观察结果动态调整,这种 “走一步看一步” 的逻辑在中等复杂度任务(如单文件生成、简单数据查询)中表现出色,但面对多步骤、长流程、强依赖的复杂任务(如 “搭建一个包含前端页面、后端接口、数据库的博客系统”“分析某行业近 5 年数据并生成多维度可视化报告”)时,会暴露两个核心问题:
缺乏全局规划:ReAct 的思考仅聚焦于 “当前 step 该做什么”,无法提前梳理任务的完整链路。例如,在开发博客系统时,ReAct 可能先调用工具创建前端 HTML 文件,后续才发现未规划后端接口格式,导致前端代码需要反复修改,效率低下。
步骤依赖管理薄弱:当任务包含 “先创建数据库表→再开发后端接口→最后对接前端” 这类强依赖步骤时,ReAct 无法提前识别依赖关系,可能出现 “先写接口再建表” 的逻辑错误,需要多次回滚调整。
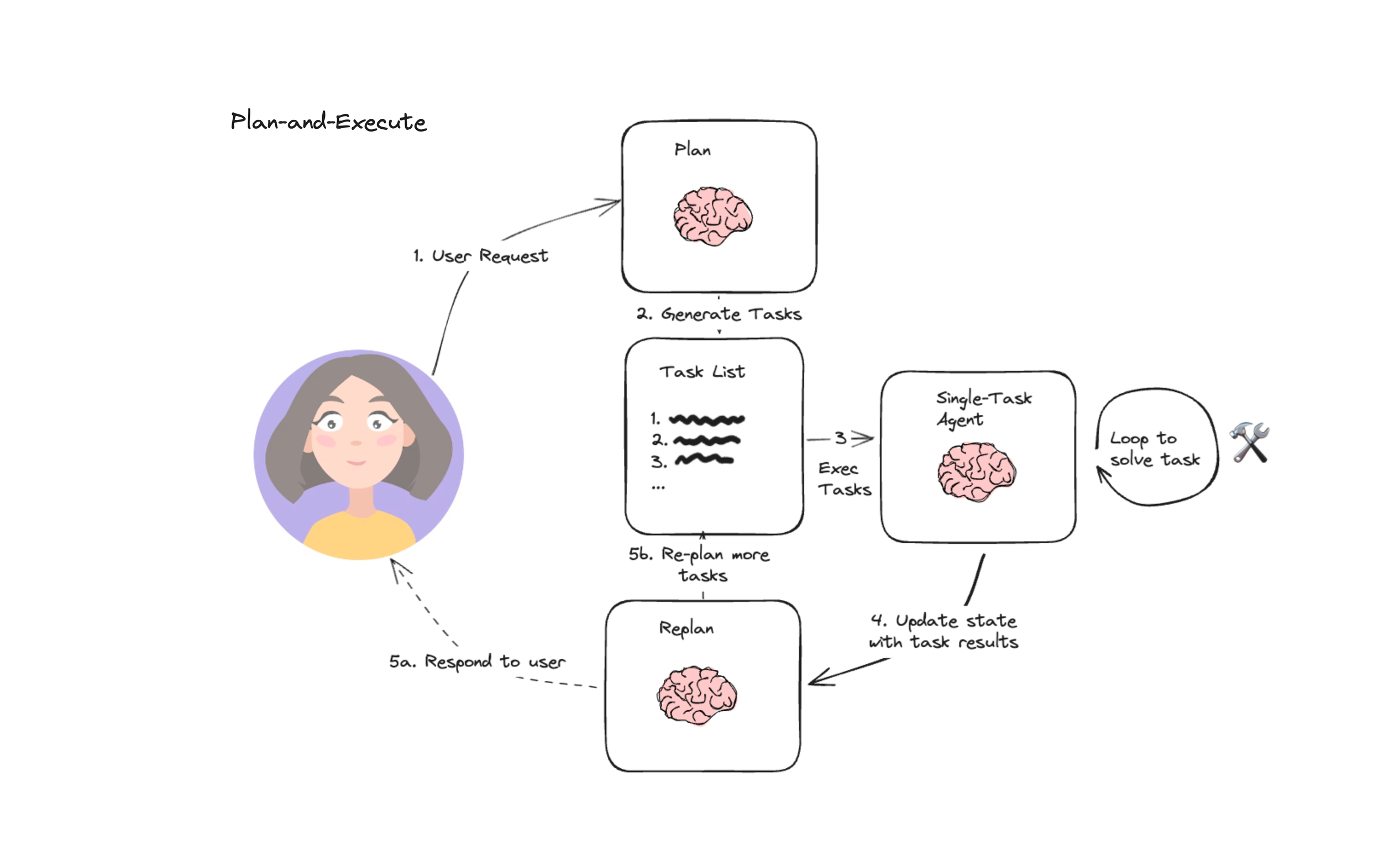
为解决上述问题,LangChain 在 ReAct 模式的基础上,提出了Plan and Execute(规划 - 执行)模式—— 它将 “任务拆解” 与 “步骤执行” 拆分为两个独立模块,通过 “先全局规划、再分步执行、动态修正” 的逻辑,大幅提升了 Agent 在复杂任务中的稳定性与效率。该模式尤其适用于需要 “多工具协同、长流程管控、步骤依赖处理” 的场景,是当前 LangChain 生态中处理复杂任务的核心范式之一。
5.1 规划-执行模式的核心逻辑
LangChain 的 Plan and Execute 模式,本质是将 Agent 的能力拆解为 “规划器(Planner)” 与 “执行器(Executor)” 两个核心模块,通过 “规划→执行→反馈→修正规划” 的闭环,实现复杂任务的系统化处理。其核心逻辑可概括为:
规划阶段(Plan):规划器接收用户的原始任务后,基于任务目标拆解出全局步骤清单,明确每个步骤的目标、所需工具、依赖关系(如 “步骤 3 需在步骤 1、2 完成后执行”),甚至会预估每个步骤的执行结果。
执行阶段(Execute):执行器按照规划器输出的步骤清单,逐一调用工具执行操作,并实时将执行结果反馈给规划器。
动态修正(Revise):规划器根据执行器返回的结果(成功 / 失败 / 异常),判断是否需要调整步骤清单 —— 例如,某步骤执行失败时,规划器会重新规划 “替代方案步骤”;某步骤结果超出预期时,规划器会简化后续步骤。
这种 “先规划后执行” 的逻辑,相当于为 Agent 增加了 “任务指挥官”(规划器)和 “操作执行者”(执行器),二者分工协作,既保证了任务的全局合理性,又确保了步骤的落地可行性。
sequenceDiagram
participant 用户
participant Agent主程序
participant Plan模型
participant Re_Plan模型
participant 执行Agent
autonumber
用户->>+Agent主程序: 今年澳网男子冠军的家乡是哪里?
Agent主程序->>+Plan模型: 请给出执行计划(Plan)
Plan模型->>-Agent主程序: 执行计划如下: ...
loop 重复n次
Agent主程序->>+执行Agent: 请执行第一步(Execute)
执行Agent->>-Agent主程序: 执行完毕,结果如下......
Agent主程序->>+Re_Plan模型: 请给出一个新的执行计划(Replan)
Re_Plan模型->>-Agent主程序: 新的执行计划如下: ......
end
Agent主程序 ->> -用户: 返回最终结果5.2 Replan 阶段存在的意义
读到这里,你或许又有一个疑问,既然第一步已经制定好计划了,按照计划按部就班的执行就好了,为啥每一次调用工具后都会根据工具的输出结果进行 Replan(重新制定计划)。
在 “2025 年斯诺克世锦赛决赛冠军是哪里人” 的 Plan-and-Execute 执行流程中,Replan(重规划)阶段是衔接 “已执行结果” 与 “剩余计划” 的核心调节环节,其意义并非单纯重复 “规划” 动作,而是解决 “初始计划与实际执行场景不匹配” 的问题,确保整个流程能动态适配复杂、不确定的任务环境,具体可从以下 4 个关键维度展开:
5.2.1 修正初始计划的 “信息盲区”,避免无效执行
初始规划阶段依赖的是 “基于问题的预设逻辑”(如默认先查冠军姓名、再查国籍),但实际执行中可能因信息缺失或场景变化,导致原计划步骤失效或冗余 —— Replan 阶段的核心作用之一,就是用 “已执行步骤的真实结果” 填补初始盲区,调整计划方向。以本问题为例:
- 若执行 “步骤 1:查 2025 斯诺克世锦赛结果” 时,搜索工具返回 “2025 年斯诺克世锦赛因赛事调整,延期至 2025 年 6 月举办,当前(执行时)决赛尚未进行”,此时初始计划中 “查冠军姓名→查国籍” 的步骤已无法推进;
- Replan 阶段会基于这一结果,重新生成适配的计划:
["记录2025斯诺克世锦赛延期后的举办时间(2025年6月)","待赛事决赛结束后,检索冠军姓名","根据冠军姓名查询国籍","整理最终答案"],避免继续执行 “查已结束赛事结果” 这类无效步骤。
5.2.2 补充任务中的 “隐性歧义”,确保答案准确性
用户问题中可能存在未明确的隐性需求(如 “斯诺克世锦赛” 可能包含男子 / 女子项目,“哪里人” 可能需区分 “国籍” 或 “出生地”),初始规划阶段可能因 “默认假设”(如默认男子项目)遗漏关键判断步骤 ——Replan 阶段会通过 “已执行结果反推需求”,补充必要的验证环节。以本问题为例:
- 若执行 “步骤 1:查冠军姓名” 时,搜索结果同时出现 “男子单打冠军 XX” 和 “女子单打冠军 YY”(用户未明确性别),此时初始计划中 “直接查冠军国籍” 的步骤会导致答案歧义;
- Replan 阶段会基于这一结果,插入补充步骤:
["向用户确认需查询的是男子还是女子斯诺克世锦赛冠军","根据用户反馈,定位对应性别的冠军姓名","查询该冠军的国籍及出生地","整理答案"],避免因初始假设偏差导致最终答案错误。
5.2.3 应对执行中的 “工具局限性”,保障流程连续性
Plan-and-Execute 模式依赖外部工具(如搜索工具、数据库)完成执行,但工具可能存在 “数据不全、接口故障” 等问题,导致单个步骤执行结果不完整 —— Replan 阶段可基于 “不完整结果” 调整工具调用策略或步骤顺序,避免流程卡在 “工具失效” 环节。以本问题为例:
- 执行 “步骤 2:查冠军国籍” 时,若调用的基础搜索工具仅返回 “冠军 XX 来自欧洲”,未明确具体国家(工具数据不全),此时原计划中 “整理‘姓名 + 国家’答案” 的步骤无法完成;
- Replan 阶段会基于这一不完整结果,调整计划:
["更换工具(如调用World Snooker Tour官网的选手档案库),查询XX的详细国籍信息","若官网无数据,补充搜索XX的采访报道或社交媒体个人资料","确认国籍后,整理最终答案"],通过切换工具或补充检索路径,确保流程能继续推进。
5.2.4 终止 “冗余步骤”,避免资源浪费
当已执行步骤的结果已足够生成最终答案,或任务目标因外部因素无需继续推进时,Replan 阶段会判断 “剩余计划是否必要”,及时终止冗余步骤,节省工具调用成本(如搜索 API 次数)和时间成本。以本问题为例:
- 若执行 “步骤 1:查冠军姓名” 时,搜索结果直接显示 “2025 斯诺克世锦赛男子单打冠军为中国选手丁俊晖,出生地江苏宜兴”(一步获取姓名 + 国籍 + 出生地),此时初始计划中 “步骤 2:查国籍”“步骤 3:整理答案” 已部分冗余;
- Replan 阶段会基于这一结果,直接调整计划:
["基于已获取的‘丁俊晖+中国+江苏宜兴’信息,整理为‘2025年斯诺克世锦赛男子单打冠军是中国江苏人丁俊晖’的最终答案"],删除原计划中 “单独查国籍” 的冗余步骤,直接进入答案整理环节。
本文只是引出 Plan-and-Execute 模式,有兴趣的读者可以深入了解,可以参考 LangChain 官方博文:《Plan-and-Execute》
六. 总结
本文从概念、原理到实践,完整剖析了 ReAct 模式 Agent 的核心逻辑,并延伸对比了 LangChain Plan and Execute 模式。
ReAct 模式以 “思考 - 行动 - 观察” 的 TAO 循环为核心,通过结构化 Prompt 引导 LLM 决策,结合工具调用与上下文更新形成闭环,解决了单纯 LLM 无法对接外部环境、完成中等复杂度任务(如单文件生成、简单数据查询)的痛点。文中 Python 实现案例进一步验证了该模式的落地可行性 —— 无需复杂算法,仅通过 Prompt 工程与基础工具封装,即可让 Agent 具备自主拆解任务、执行操作的能力。
而 LangChain Plan and Execute 模式则是对 ReAct 的进阶优化,通过拆分 “规划器” 与 “执行器” 模块,先制定全局步骤清单、再分步执行并动态修正,弥补了 ReAct 在复杂任务中 “缺乏全局规划、步骤依赖管理薄弱” 的不足,更适配多工具协同、长流程管控的场景(如系统搭建、多维度数据分析)。
两种模式各有侧重:ReAct 灵活轻便,适合快速落地中低复杂度任务;Plan and Execute 严谨系统,更适合处理强依赖、长流程的复杂需求。二者共同构成了 LLM Agent 从 “文本生成” 向 “实用任务解决” 迈进的核心技术框架,为不同场景下的 Agent 开发提供了清晰的实践路径,也为后续更智能、更高效的 Agent 范式演进奠定了基础。