初探Nebula Graph核心架构设计
初探Nebula Graph核心架构设计
图数据结构天然适配风控场景的关联关系建模————将用户、商户、设备、账户等实体抽象为 “点”,注册登录、交易支付、设备绑定等行为抽象为 “边”,可直观呈现复杂风险网络,而随着互联网与金融业务发展,风控图谱已突破千亿顶点、万亿边规模,且需支持毫秒级多跳查询、灵活关联遍历等高频需求,传统关系型数据库的多表 join 操作在多跳查询时性能呈指数级衰减,NoSQL 数据库缺乏原生图语义支持,传统图数据库难以兼顾超大规模存储与高并发查询,这一痛点催生了高性能分布式图数据库的需求,Nebula Graph 凭借存算分离、Shared-nothing 分布式存储、Raft 一致性协议等核心设计,可实现千亿级数据高效存储与毫秒级查询响应,本文将从架构原理、存储设计、查询流程等维度,对其核心技术设计进行初步介绍与梳理。
一. 整体架构设计
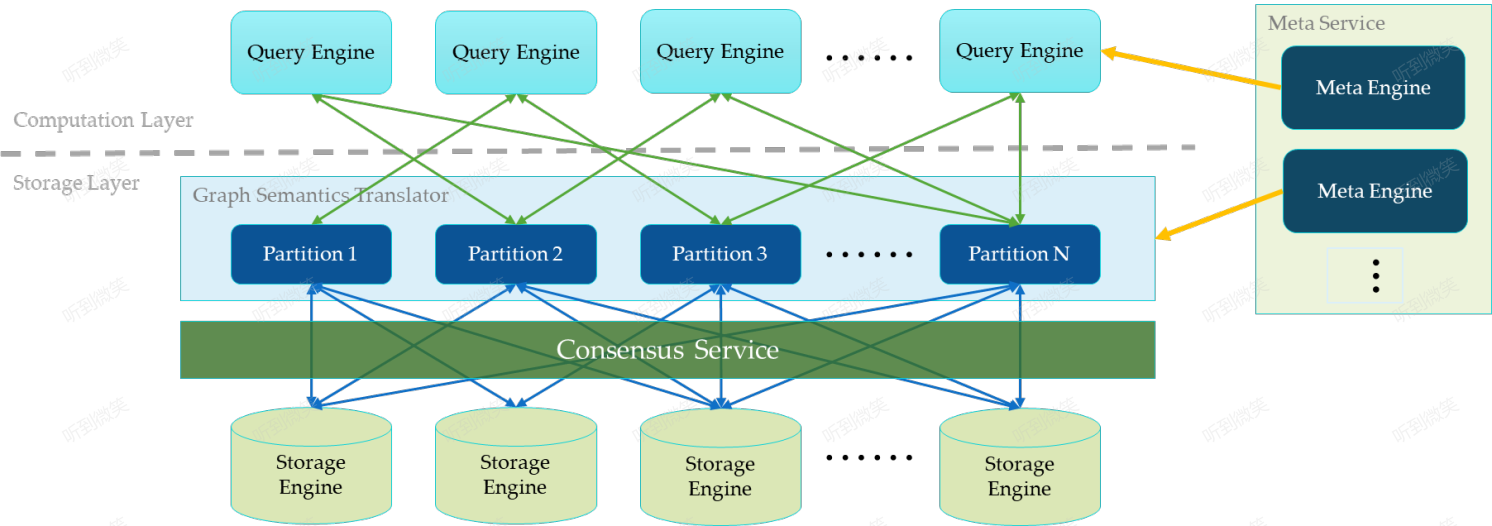
一个完整的 Nebula Graph 部署集群包含三个服务,即 Query Service,Storage Service 和 Meta Service。每个服务都有其各自的可执行二进制文件,这些二进制文件既可以部署在同一组节点上,也可以部署在不同的节点上。
1.1 Meta Service:集群的 “大脑与配置中心”
Meta Service 作为 Nebula Graph 集群的核心管控组件,承担着全集群元数据管理与运维调度的双重职责,是保障集群稳定运行的 “大脑与配置中心”。其管理的元数据覆盖四大核心维度:图空间(Space)的全局配置(如 Partition 数量、副本数)、Schema 定义(包括点 / 边类型的结构、属性数据类型及约束)、用户及角色的权限矩阵(如读写权限、Space 访问权限),以及集群拓扑与数据分布信息(如 Partition 与 StorageD 节点的映射关系、Raft Group 的 Leader/Follower 状态)。
在高可用设计上,Meta Service 基于 Raft 共识协议实现数据同步与故障转移,因此通常要求部署奇数个节点(推荐 3 或 5 个),确保在部分节点宕机时仍能维持集群元数据的一致性与服务可用性。从集群协作流程来看,所有元数据变更操作(如创建 Space、新增 Storage 节点、修改 Schema)均需通过 Meta Service 发起并同步至全集群;而 GraphD(计算节点)与 StorageD(存储节点)在启动时,会主动向 Meta Service 注册节点信息,并实时拉取最新的集群状态(如 Partition 分布、Leader 位置),确保计算层与存储层的协同一致性。
1.2 存算分离架构
架构图中 Meta Service 左侧为 Nebula Graph 的核心服务集群,其采用存储与计算分离的经典架构设计(以虚线为界,上层为计算层,下层为存储层)。这种架构通过解耦数据存储与计算任务,带来三大核心价值,且各优势层层递进:
- 独立弹性伸缩:计算层(Query Service)的负载特征为高并发、短查询,存储层(Storage Service)则侧重海量数据持久化与 I/O 密集型操作,两者资源需求差异显著。存算分离允许单独对计算层或存储层进行扩容 / 缩容 —— 例如业务高峰期仅增加 GraphD 节点应对查询压力,数据量激增时单独扩展 StorageD 节点提升存储能力,无需整体扩容,大幅降低资源浪费。
- 无限水平扩展:得益于计算层无状态设计与存储层 Shared-nothing 分布式架构,存算分离彻底突破单机硬件资源限制。集群可通过持续增加计算节点或存储节点,实现查询吞吐量与数据存储容量的线性增长,轻松支撑从亿级到千亿级数据规模的平滑扩展。
- 多计算引擎适配:存储层(Storage Service)抽象为统一的数据服务层,脱离了对单一计算层的依赖。除了优先支撑 Query Service 处理实时查询请求外,还可灵活对接各类计算引擎 —— 例如适配 Spark/Flink 等迭代计算框架处理离线批处理任务,或对接机器学习引擎实现图算法训练,让存储资源复用率最大化,构建更灵活的计算生态。
1.3 无状态计算层(GraphD)
现在我们来看下计算层,每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取元数据信息,以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。
计算层的负载均衡有两种形式,最常见的方式是在计算层上加一个负载均衡,第二种方法是将计算层所有节点的 IP 地址配置在客户端中,这样客户端可以随机选取计算节点进行连接。
每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。
1.4 Shared-nothing 分布式存储层(StorageD)
Storage Service 采用 shared-nothing 的分布式架构设计,每个存储节点都有一个或多个本地 KV 存储实例(默认是RocksDB)作为物理存储。Nebula 采用多数派协议 Raft 来保证这些 KV 存储之间的一致性(由于 Raft 比 Paxo 更简洁,Nebula Graph 选用了 Raft)。在 KVStore 之上是图语义层,用于将图操作转换为下层 KV 操作。
图数据(点和边)是通过 Hash 的方式存储在不同 Partition 中。这里用的 Hash 函数实现很直接,即 vertex_id 取余 Partition 数。在 Nebula Graph 中,Partition 表示一个虚拟的数据集,这些 Partition 分布在所有的存储节点,分布信息存储在 Meta Service 中(因此所有的存储节点和计算节点都能获取到这个分布信息)。
1.5 核心特性
Nebula Graph 基于 C++ 实现,架构设计支持存储千亿顶点、万亿边,并提供毫秒级别的查询延时。我们在 3 台 48U192G 物理机搭建的集群上灌入 10 亿美食图谱数据对 Nebula Graph 的功能进行了验证。
- 一跳查询 TP99 延时在 5ms 内,两跳查询 TP99 延时在 20ms 内,一般的多跳查询 TP99 延时在百毫秒内。
- 集群在线写入速率约为20万 Records/s。
- 支持通过 Spark 任务离线生成 RocksDB 底层 SST File,直接将数据文件载入到集群中,即类似 HBase BulkLoad 能力。
- 提供了类 SQL 查询语言,对于新增的业务需求,只需构造 Nebula Graph SQL 语句,易于理解且能满足各类复杂查询要求。
- 提供联合索引、GEO 索引,可通过实体属性或者关系属性查询实体、关系,或者查询在某个经纬度附近 N 米内的实体。
- 一个 Nebula 集群中可以创建多个 Space (概念类似 MySQL 的DataBase),并且不同 Space 中的数据在物理上是隔离的。
二. 存储设计
2.1 Partition:逻辑分片的基本单位
在 Nebula Graph 中,Partition 是图数据水平分片的最小逻辑单元。每个图空间(Space)在创建时需指定 Partition 的数量(例如 100、1000 等),该数值一旦设定便不可更改。所有点(Vertex)和边(Edge)根据其 Vertex ID 通过哈希函数映射到具体的 Partition:
1 | PartitionID = hash(VertexID) % PartitionCount |
这一机制确保了:
- 同一个顶点的所有属性(Tag)和出边(Outgoing Edges)必然落在同一个 Partition 中;
- 查询邻接关系时,无需跨 Partition 拉取数据,极大提升了遍历效率;
- 数据分布尽可能均匀(前提是 Vertex ID 具备良好散列性)。
📌 注意:Nebula 默认仅存储出边。若需高效查询入边(In-Edges),可显式创建反向边(Reverse Edge),此时反向边将根据目标顶点的 ID 被分配到其所属的 Partition。
2.2 Partition 与 Storage Service 的物理映射
虽然 Partition 是逻辑概念,但它必须部署在物理的 Storage Service(StorageD)节点上。Meta Service 负责维护全局的 Partition 分布表,记录每个 Partition 的副本位于哪些 StorageD 节点。
- 每个 Partition 可配置多个副本(通常为 3 副本),组成一个 Raft Group;
- Raft 协议在副本间选举 Leader,所有读写请求均由 Leader 处理,并通过日志复制同步到 Follower;
- 当某 StorageD 节点宕机,Meta Service 会触发自动故障转移(Failover),从存活副本中重新选举 Leader,保障服务连续性。
值得注意的是:一个 StorageD 节点通常托管多个 Partition(包括主副本和从副本),而非“一个 Partition 对应一个进程或文件”。
2.3 底层存储引擎:共享 RocksDB 实例
Nebula Graph 的 Storage Service 底层使用 RocksDB 作为本地 KV 存储引擎。每个 StorageD 节点默认配置下仅运行一个 RocksDB 实例。那Storage Service 如何实现多 Partition 共存?
答案在于 Key 编码设计。Nebula 将 Partition ID 作为所有 Key 的前缀,使得不同 Partition 的数据在同一个 RocksDB 中逻辑隔离。典型 Key 结构如下:
点(Vertex)属性 Key:

Type:1 个字节,用来表示 key 类型,当前的类型有 data, index, system 等Part ID:3 个字节,用来表示数据分片 Partition,此字段主要用于 Partition 重新分布(balance) 时方便根据前缀扫描整个 Partition 数据Vertex ID:8 个字节, 用来表示点的 IDTag ID:4 个字节, 用来表示关联的某个 tagTimestamp:8 个字节,对用户不可见,未来实现分布式事务(MVCC)时使用
边(Edge)Key(出边):

Type:1 个字节,用来表示 key 的类型,当前的类型有 data, index, system 等。Part ID:3 个字节,用来表示数据分片 Partition,此字段主要用于 Partition 重新分布(通过 BALANCE 命令)时方便根据前缀扫描整个 Partition 数据Vertex ID:8 个字节, 出边里面用来表示源点的 ID, 入边里面表示目标点的 ID。Edge Type:4 个字节, 用来表示这条边的类型,如果大于 0 表示出边,小于 0 表示入边。Rank:8 个字节,用来处理同一种类型的边存在多条的情况。用户可以根据自己的需求进行设置,这个字段可存放交易时间、交易流水号、或某个排序权重(比如,定义一个 edge type “转账”,用户 A 可能多次转账给 B, 所以 Nebula 又增加了一个 Rank 字段来做区分,表示 A 到 B 之间多次转账记录。)Vertex ID:8 个字节,出边里面用来表示目标点的 ID, 入边里面表示源点的 ID。Timestamp:8 个字节,对用户不可见,未来实现分布式做事务的时候使用。
由于 RocksDB 底层使用 LSM-Tree(Log-Structured Merge-Tree) 作为其核心存储结构,它将所有写入先缓存在内存中的有序结构(MemTable),再批量顺序刷入磁盘形成不可变的 SSTable 文件,并通过后台 Compaction 合并多层文件以维持读取效率。这种设计天然支持高效的范围查询和前缀扫描(Prefix Seek)——因为 SSTable 中的键是全局有序的。因此,StorageD 可以快速定位某个 Partition 内的所有数据(只需指定 Type + Part ID 作为前缀),或高效遍历某顶点的所有出边,从而在单个 RocksDB 实例中实现多个 Partition 的高性能共存与隔离。
✅ 优势:
- 避免为成百上千个 Partition 启动独立 RocksDB,节省内存与文件句柄;
- 全局 Compaction、WAL、缓存策略更易优化;
- 利用 RocksDB 的前缀 Bloom Filter 加速 Partition 内查询。
虽然在默认配置下,一个 StorageD 实例仅使用一个 RocksDB 实例,但这并不意味着 Nebula Graph 限制为只能使用单一 RocksDB。实际上,Nebula Graph 支持 多 RocksDB 实例 的设计:每个配置的 data_path 路径对应一个独立的 RocksDB 实例。
这一机制充分考虑了现代服务器通常配备多块物理磁盘的硬件特性。通过在 data_path 中指定多个存储路径(以逗号分隔),Nebula Graph 会为每个路径启动一个独立的 RocksDB 实例。这种设计不仅能够提升 I/O 并行度,还能更高效地利用本地存储资源,从而显著增强系统的整体吞吐能力和写入性能。
例如,若配置如下:
1 | data_path=/disk1/nebula/data,/disk2/nebula/data,/disk3/nebula/data |
则 StorageD 将分别在三块磁盘上管理三个 RocksDB 实例,Partition 数据会按策略分布到这些实例中,实现物理层面的 I/O 负载分散。
Storage 服务配置 - NebulaGraph Database 手册

2.4 图数据的 KV 映射逻辑
Nebula 将图模型“拍平”为一系列 KV 对,以支持高效的随机读写和范围扫描。
2.4.1 点的存储
每个顶点可拥有多个 Tag(标签),每个 Tag 定义一组属性。例如,顶点 "user101" 可同时具有 Person 和 Employee 两个 Tag。
- 每个 Tag 对应一个独立的 KV 条目;
- Value 为序列化后的属性值(如 JSON 或自定义二进制格式);
- 查询时,只需根据 VertexID + TagID 定位 Key,一次 Get 即可返回全部属性。
2.4.2 边的存储
边按 源顶点(Src)组织,Key 中包含源点 ID、边类型、排序字段(Ranking)和目标点 ID。
- Ranking 字段用于支持多边(如多次转账记录)的排序与去重;
- 边属性存储在 Value 中;
- 遍历邻居时,StorageD 可对
[SrcVertexID][EdgeType]前缀执行 Range Scan,高效获取所有邻接点。
这种设计天然支持 局部性优化:点及其出边物理相邻,减少 I/O 跳数。
三. 查询执行流程示例
1 | GO FROM "user101" OVER friend YIELD dst(edge) |
执行过程如下:
GraphD(计算层) 接收请求,解析 nGQL 语句;
根据
"user101"计算其所属 Partition:P = hash("user101") % N;向 Meta Service 查询 Partition
P的 Leader 所在 StorageD 地址;向该 StorageD 发起 RPC,请求
"user101"的friend类型出边;StorageD
1
Key Range: [P]["user101"][friend][min_rank] ~ [P]["user101"][friend][max_rank]
返回所有目标顶点 ID 列表;
GraphD 汇总结果并返回客户端。
整个过程最多一次网络跳转(若无多跳),且 StorageD 本地完成大部分计算(如过滤、投影),极大降低延迟。
四. Partition Raft同步原理
Nebula Graph 采用 Raft 协议保证 Partition 副本间的数据一致性。下面我们以一个典型的写入操作为例,详细解析 Raft 同步的完整流程。
4.1 写入请求的 Raft 同步触发时机
当客户端发送写入请求(如插入顶点或边)时,整个处理流程涉及多个组件的协同工作。Raft 同步并非在接收到请求后立即开始,而是经过一系列前置处理后,在特定时机触发。
4.2 Raft 日志复制与提交完整流程
以下是 Raft 同步的核心流程,从客户端请求到数据持久化的完整路径:
sequenceDiagram
participant Client as 客户端
participant GraphD as GraphD<br/>(计算层)
participant Meta as Meta Service
participant Leader as StorageD Leader<br/>(Partition Leader)
participant Follower1 as StorageD Follower1
participant Follower2 as StorageD Follower2
participant RocksDB as 本地RocksDB
Client->>GraphD: 发送写入请求
GraphD->>GraphD: 解析nGQL,计算Partition ID
GraphD->>Meta: 查询Partition Leader地址
Meta-->>GraphD: 返回Leader地址
GraphD->>Leader: 发送写入请求
Leader->>Leader: 合法性校验
Leader->>Leader: 编码为Raft日志
Leader->>Leader: 写入本地WAL
Leader->>Follower1: 复制日志(AppendEntries)
Leader->>Follower2: 复制日志(AppendEntries)
Follower1->>Follower1: 写入本地WAL
Follower2->>Follower2: 写入本地WAL
Follower1-->>Leader: 确认复制成功
Follower2-->>Leader: 确认复制成功
Leader->>Leader: 多数派确认(2/3)
Leader->>Leader: 更新committedLogId
Leader->>RocksDB: 批量应用日志到RocksDB
RocksDB-->>Leader: 写入完成
Leader-->>GraphD: 返回成功响应
GraphD-->>Client: 返回写入结果
Note over Leader,Follower1: 异步过程
Leader->>Follower1: 携带新committedLogId
Leader->>Follower2: 携带新committedLogId
Follower1->>Follower1: 应用日志到RocksDB
Follower2->>Follower2: 应用日志到RocksDB4.2.1 请求路由阶段
客户端请求 :客户端发送 nGQL 写入语句到任意 GraphD 节点
GraphD 解析 :解析语句,确定操作类型和涉及的顶点/边
Partition 计算 :根据顶点 ID 通过哈希算法计算所属 Partition ID
Leader 查询 :向 Meta Service 请求该 Partition 的 Leader 所在 StorageD 地址
请求转发 :将写入请求发送到对应的 StorageD Leader 节点
4.2.2 Leader 处理阶段
- 请求校验 :检查 Schema 合法性、权限等
- 日志编码 :将写入操作转换为结构化的 Raft 日志条目
- WAL 写入 :将日志追加到本地 WAL(Write-Ahead Log),确保数据持久化
- 触发复制 :调用 Raft 协议的日志复制机制
4.2.3 日志复制阶段
- 复制请求 :Leader 向所有 Follower 发送 AppendEntries RPC
- Follower 处理 :
- 验证日志连续性和完整性
- 将日志写入本地 WAL
- 返回确认响应
- 多数派确认 :Leader 统计确认响应,当达到多数派阈值(如 3 副本集群中收到 2 个确认)时,日志被标记为可提交
4.2.4 日志提交阶段
- 更新提交点 :Leader 更新已提交日志的最高 ID(committedLogId)
- 批量应用 :将所有已提交但未应用的日志批量写入 RocksDB
- 创建 WriteBatch,批量执行 PUT/REMOVE 等操作
- 调用 RocksDB 的批量写入 API,提高写入效率
- 响应客户端 :写入完成后,返回成功响应给 GraphD,最终传递给客户端
4.2.5 Follower 同步阶段
- 提交信息同步 :Leader 在后续 AppendEntries 请求中携带新的 committedLogId
- Follower 日志应用 :Follower 发现本地有已复制但未提交的日志时,自动将其应用到 RocksDB
- 状态一致 :最终所有副本的 RocksDB 中的数据达到一致状态
4.3 Raft 同步的设计优势
Raft一致性协议流程可参考:深度解析 Raft 分布式一致性协议 | 听到微笑的博客
强一致性保障
- 基于多数派确认机制,确保数据在副本间的最终一致性
- 自动故障转移,当 Leader 宕机时,从存活副本中重新选举 Leader
高性能写入
- 批量日志复制,减少网络传输开销
- 顺序写入 WAL,避免随机 I/O,提高写入性能
- 批量应用到 RocksDB,减少磁盘写入次数
资源高效利用
- 多个 Partition 共享同一 RocksDB 实例,减少内存占用和文件句柄消耗
- 统一的存储管理,便于优化和维护
灵活的配置选项
- 支持调整副本数量,平衡一致性与性能
- 可配置 WAL 同步策略,根据业务需求调整可靠性级别
- 支持快照频率调整,平衡存储开销与恢复速度
4.4 Raft 同步与 RocksDB 的关系
Raft 同步与 RocksDB 是两个独立的层次:
- Raft 层 :负责分布式一致性,确保日志在副本间同步
- 存储层 :负责数据持久化,将已提交的日志写入 RocksDB
- 解耦设计 :Raft 层不直接操作 RocksDB,而是通过抽象接口与存储层交互
- 批量写入 :Raft 层将多个日志批量传递给存储层,存储层批量写入 RocksDB,提高效率
五. 总结
Nebula Graph 通过 Meta Service + 无状态计算层 + Shared-nothing 存储层 的三层架构,实现了高可用、高扩展的分布式图数据库系统。其核心设计亮点包括:
- 静态哈希分片(即 Partition 数量创建后不可修改):以 Vertex ID 为分片键(PartitionID = hash (VertexID) % PartitionCount),保证点与出边归属同一 Partition,且 Partition 数量创建后不可修改(即‘静态’),兼顾查询效率与集群稳定性;
- 共享 RocksDB 实例:通过 Key 前缀实现多 Partition 逻辑隔离,兼顾性能与资源效率;
- Raft 多副本一致性:保障数据可靠性与自动容灾;
- 存算分离:计算层无状态,易于云原生部署;存储层专注数据持久化与局部计算。
这种架构使 Nebula Graph 能够支撑 千亿级顶点、万亿级边 的超大规模图场景,同时保持毫秒级查询响应,适用于社交网络、金融风控、知识图谱等对关联分析要求极高的业务领域。
参考文章:
NebulaGraph 数据库架构——概览 — NebulaGraph Database Architecture — A Bird’s Eye View
NebulaGraph 存储引擎简介 — An Introduction to NebulaGraph’s Storage Engine