本文讲述一个由 ShardingJDBC 使用不当引起的悲惨故事。
一. 问题重现 有一天运营反馈我们部分订单状态和第三方订单状态无法同步。
根据现象找到了不能同步订单状态是因为 order 表的 thirdOrderId 为空导致的,但是这个字段为啥为空,排查过程比较波折。
过滤掉复杂的业务逻辑,当时的代码可以简化为这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Order order; if (特定条件) { order = buildOrders(); orderService.saveBatch(Lists.newArrayList(order)); } ThirdOrder thirdOrder = callThirdPlaceOrder()order.setThirdOrderId(thirdOrder.getOrderId()); orderItems.foreach(e -> e.setThirdOrderId(thirdOrder.getOrderId())); orderService.updateById(order); orderItemService.updateBatchById(itemUpdateList);
我们发现这类有问题的订单,order 表 thirdOrderId 为空,但是 order_item 表 thirdOrderId 更新成功了,使我们直接排除了这里母单更新“失败”的问题,因为两张表的更新操作在一个事务里面,子单更新成功了说明这里的代码逻辑应该没有问题。
就是这里的错觉,让我们走了很多弯路。我们排查了所有可能存在并发更新、先读后写、数据覆盖的地方,结合业务日志,翻遍了业务代码仍然无法确认问题具体在哪里。最后只能在可能出现问题的地方补充了日志,同时我们也在此处更新 order 表的地方加上了日志,最后发现在执行 orderService.saveBatch 后 order 的 id 为空,导致 order 的更新并没有成功。
说实话找到问题的那一刻有点颠覆我的认知,在我的印象中,MyBatisPlus批量插入的方法是可以返回ID,经过实验,在当前项目环境中,save()方法会返回主键ID,但是saveBatch()方法不会。这种颠覆认知的新
二. 源码分析 2.1 JDBC如何获取批量插入数据的ID 要想摸清楚批量插入后为什么没有获取到主键ID,我们得先了解一下JDBC如何批量插入数据,以及在批量插入操作后,获取数据库的主键值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 PreparedStatement pstmt = conn.prepareStatement("INSERT INTO order_info (column1, column2) VALUES (?, ?)" , Statement.RETURN_GENERATED_KEYS);pstmt.setString(1 , "value1" ); pstmt.setString(2 , "value2" ); pstmt.addBatch(); pstmt.executeBatch(); ResultSet generatedKeys = pstmt.getGeneratedKeys();while (generatedKeys.next()) { int primaryKey = generatedKeys.getInt(1 ); System.out.println("Generated Primary Key: " + primaryKey); } generatedKeys.close(); pstmt.close(); conn.close();
在执行批量插入操作后,我们可以通过 Statement.getGeneratedKeys() 方法获取数据库主键值。
2.2 MyBatis 批量插入原理 MyBatis-Plus 是对 MyBatis 的一种增强,底层还是依赖于MyBatis SqlSession API对数据库进行的操作,而SqlSession执行批量插入大概分为如下几步:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH)) { YourMapper mapper = sqlSession.getMapper(YourMapper.class); List<YourEntity> entities = new ArrayList <>(); for (YourEntity entity : entities) { mapper.insert(entity); } sqlSession.flushStatements(); sqlSession.commit(); } catch (Exception e) { sqlSession.rollback(); }
2.3 Myabtis-Plus + ShardingJDBC 批量插入数据为什么无法获取ID MyBatis-Plus 执行批量插入操作本质上和MyBatis是一致的,Myabtis-Plus saveBtach方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Transactional(rollbackFor = Exception.class) default boolean saveBatch (Collection<T> entityList) { return saveBatch(entityList, DEFAULT_BATCH_SIZE); } @Transactional(rollbackFor = Exception.class) @Override public boolean saveBatch (Collection<T> entityList, int batchSize) { String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE); return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity)); }
进入executeBatch:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static <E> boolean executeBatch (Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) { Assert.isFalse(batchSize < 1 , "batchSize must not be less than one" ); return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> { int size = list.size(); int i = 1 ; for (E element : list) { consumer.accept(sqlSession, element); if ((i % batchSize == 0 ) || i == size) { sqlSession.flushStatements(); } i++; } }); }
在 executeBatch 中 MyBatis-Plus 会循环调用 SqlSession.insert 缓存插入语句,每 batchSize 提交一次SQL。
进入 DefaultSqlSession.flushStatements():
1 2 3 4 5 6 7 8 9 10 @Override public List<BatchResult> flushStatements () { try { return executor.flushStatements(); } catch (Exception e) { throw ExceptionFactory.wrapException("Error flushing statements. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
委托 BaseExecutor.flushStatements() 执行:
1 2 3 4 5 6 7 8 9 10 11 @Override public List<BatchResult> flushStatements () throws SQLException { return flushStatements(false ); } public List<BatchResult> flushStatements (boolean isRollBack) throws SQLException { if (closed) { throw new ExecutorException ("Executor was closed." ); } return doFlushStatements(isRollBack); }
最终 doFlushStatements() 方法由各个子类去实现,BaseExecutor 有 BatchExecutor,ReuseExecutor,SimpleExecutor,ClosedExecutor,MybatisBatchExecutor,MybatisReuseExecutor,MybatisSimpleExecutor这几种实现。
Mybatis 开头的是 Mybatis-Plus 提供的实现,分别对应 MyBatis 的 simple、reuse、batch执行器类别。不管哪个执行器,里面都会有一个 StatementHandler 接口来负责具体执行SQL。
而在 MyBatis-Plus 批量插入的场景中,是由 MybatisBatchExecutor#doFlushStatements 执行的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 @Override public List<BatchResult> doFlushStatements (boolean isRollback) throws SQLException { try { List<BatchResult> results = new ArrayList <>(); if (isRollback) { return Collections.emptyList(); } for (int i = 0 , n = statementList.size(); i < n; i++) { Statement stmt = statementList.get(i); applyTransactionTimeout(stmt); BatchResult batchResult = batchResultList.get(i); try { batchResult.setUpdateCounts(stmt.executeBatch()); MappedStatement ms = batchResult.getMappedStatement(); List<Object> parameterObjects = batchResult.getParameterObjects(); KeyGenerator keyGenerator = ms.getKeyGenerator(); if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) { Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator; jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects); } else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { for (Object parameter : parameterObjects) { keyGenerator.processAfter(this , ms, stmt, parameter); } } closeStatement(stmt); } catch (BatchUpdateException e) { StringBuilder message = new StringBuilder (); message.append(batchResult.getMappedStatement().getId()) .append(" (batch index #" ) .append(i + 1 ) .append(")" ) .append(" failed." ); if (i > 0 ) { message.append(" " ) .append(i) .append(" prior sub executor(s) completed successfully, but will be rolled back." ); } throw new BatchExecutorException (message.toString(), e, results, batchResult); } results.add(batchResult); } return results; } finally { for (Statement stmt : statementList) { closeStatement(stmt); } currentSql = null ; statementList.clear(); batchResultList.clear(); } }
在 1 处,执行批量插入语句后,然后在2处调用 Jdbc3KeyGenerator.jdbc3KeyGenerator 获取ID:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public void processBatch (MappedStatement ms, Statement stmt, Object parameter) { final String[] keyProperties = ms.getKeyProperties(); if (keyProperties == null || keyProperties.length == 0 ) { return ; } try (ResultSet rs = stmt.getGeneratedKeys()) { final ResultSetMetaData rsmd = rs.getMetaData(); final Configuration configuration = ms.getConfiguration(); if (rsmd.getColumnCount() < keyProperties.length) { } else { assignKeys(configuration, rs, rsmd, keyProperties, parameter); } } catch (Exception e) { throw new ExecutorException ("Error getting generated key or setting result to parameter object. Cause: " + e, e); } }
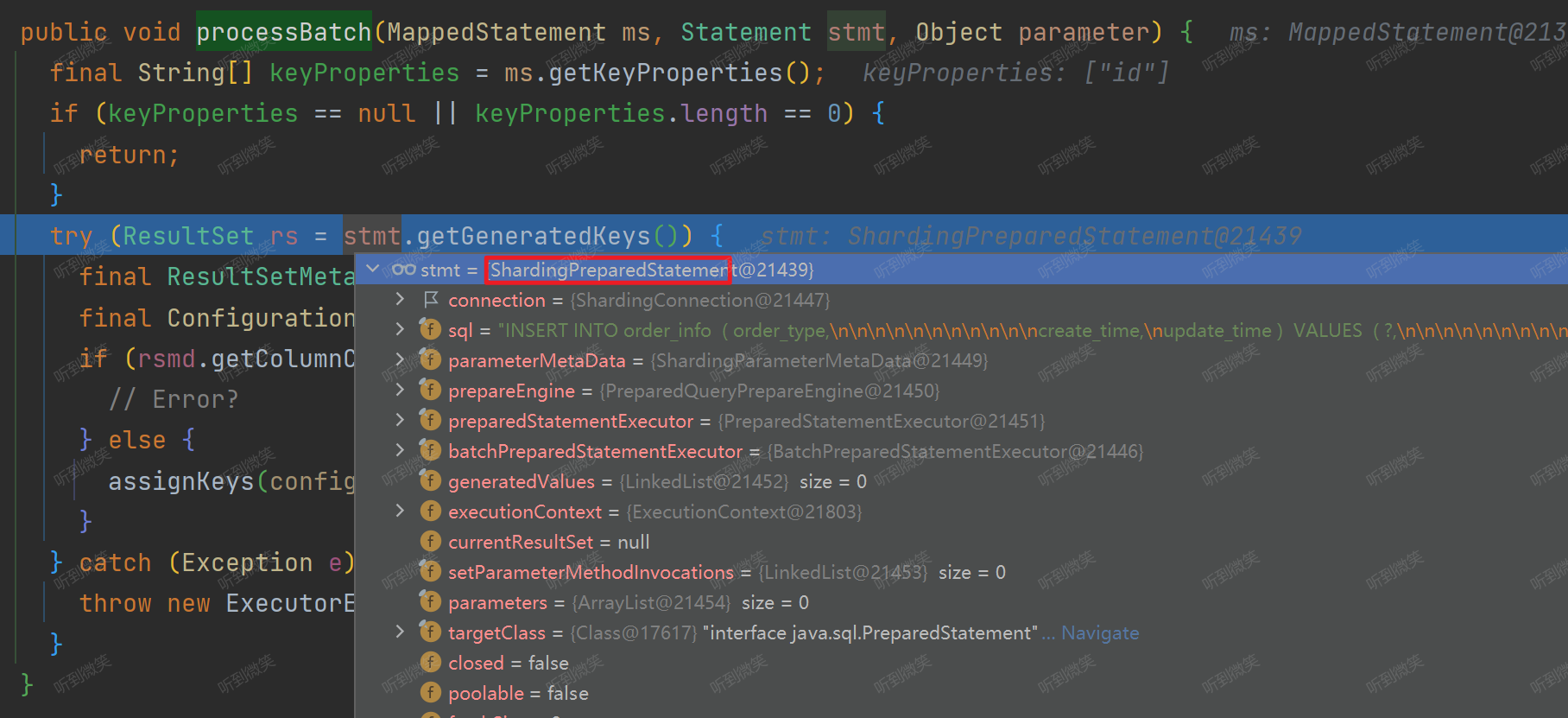
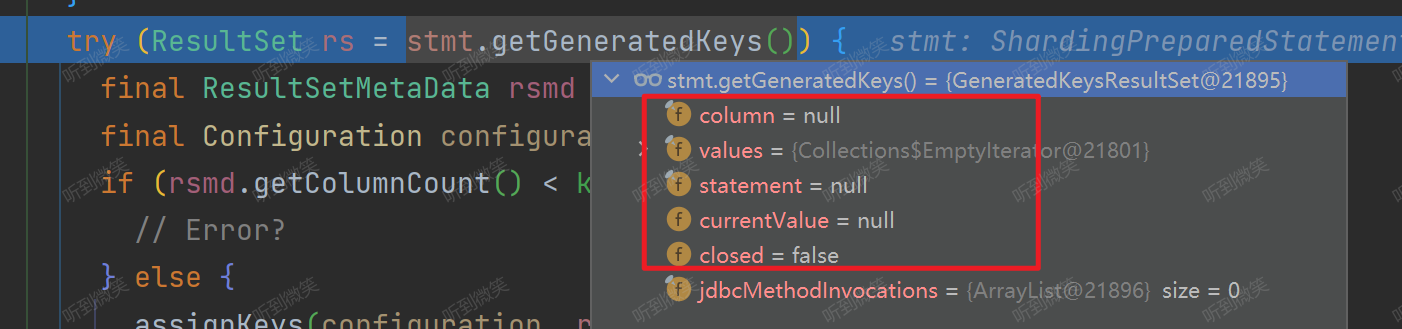
但是我们项目中如果使用的 ShardingJDBC,那么此时调用的就是 ShardingPreparedStatement.getGeneratedKeys():
通过 DEBUG,我们发现在我们项目中 ShardingPreparedStatement.getGeneratedKeys() 返回的是null值:
这也就找到了为什么MyBatis-Plus 和 ShardingJDBC 一起使用时获取不到ID值的问题,问题的根节并不在MyBatis这边,而是 ShardingJDBC 实现的 PreparedStatement 获取不到key。
2.4 为什么执行MyBatis-Plus save方法可以获取到主键 当我们调用 MyBatis-Plus save() 方法保存单条数据时,底层实际上还是调用的 ShardingPreparedStatement.getGeneratedKeys() 方法,获取插入后的主键key:
1 2 3 4 5 6 7 8 9 10 11 @Override public ResultSet getGeneratedKeys () throws SQLException { Optional<GeneratedKeyContext> generatedKey = findGeneratedKey(); if (preparedStatementExecutor.isReturnGeneratedKeys() && generatedKey.isPresent()) { return new GeneratedKeysResultSet (generatedKey.get().getColumnName(), generatedValues.iterator(), this ); } if (1 == preparedStatementExecutor.getStatements().size()) { return preparedStatementExecutor.getStatements().iterator().next().getGeneratedKeys(); } return new GeneratedKeysResultSet (); }
但是在执行单条数据插入时,1 == preparedStatementExecutor.getStatements().size() 是成立的,就会返回底层被真实被代理的MySQL JDBC 的 Statement 获取主键key:
至于 AbstractStatementExecutor.statements 为什么在执行单一语句的时候statements里不为空,但是批量插入的时候,这个list为空,可以参考下面的回答:
AbstractStatementExecutor.statements是ShardingJDBC中的一个重要数据结构,它用于存储待执行的SQL语句及其对应的数据库连接信息。在进行SQL操作时,ShardingJDBC会根据你的分片策略将SQL语句路由到相应的数据库节点,并生成对应的数据结构存储在statements这个列表里。
那么,为什么在执行单一SQL语句时,statements不为空,而在批量插入时,这个列表却为空呢?这主要是因为ShardingJDBC处理这两种情况的方式有所不同。
对于单一SQL语句,ShardingJDBC将其路由到正确的数据库节点(可能是多个),然后创建对应的PreparedStatement对象,这些对象被存储在statements列表中,以便后续执行和获取结果。
对于批量插入,ShardingJDBC采取了一种“延迟执行”的策略。具体来说,ShardingJDBC首先会解析和拆分批量插入语句,然后将拆分后的单一插入语句暂存起来,而不是立即创建PreparedStatement对象。这就导致了在批量插入过程中,statements列表为空。这样做的主要目的是为了提高批量插入的性能,因为创建PreparedStatement对象和管理数据库连接都是需要消耗资源的。
三. 总结 本文由故障现象定位到了具体的问题点是因为 MyBatis-Plus 批量插入没有返回数据库组件,而跟踪源码后我们却发现是因为ShardingJDBC不支持批量插入获取主键值。
ShardingJDBC不支持批量插入后获取主键,主要是因为在批量插入操作中,ShardingJDBC可能需要将数据插入到多个不同的数据库节点,在这种情况下,每个节点都可能有自己的主键生成规则,并且这些节点可能并不知道其他节点的主键值。因此,如果你需要在批量插入后获取自动生成的主键,可能需要通过其他方式实现,例如使用全局唯一ID作为主键。