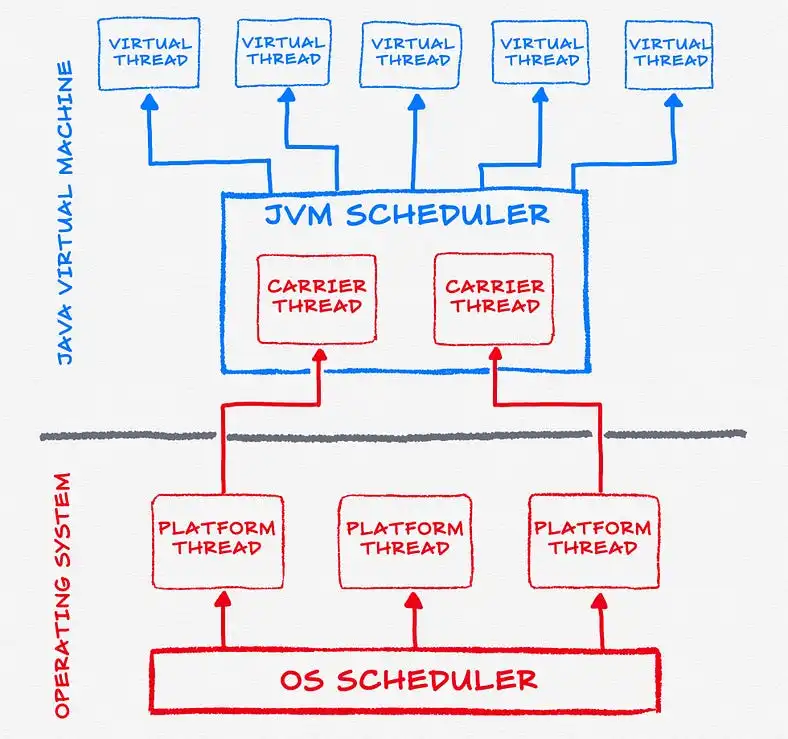
Java21 GA新特性-虚拟线程详解(转)
本文转载至:虚拟线程 - VirtualThread源码透视 - throwable - 博客园 (cnblogs.com)
一. 前提JDK19于2022-09-20发布GA版本,该版本提供了虚拟线程的预览功能。下载JDK19之后翻看了一下有关虚拟线程的一些源码,跟早些时候的Loom项目构建版本基本并没有很大出入,也跟第三方JDK如鹅厂的Kona虚拟线程实现方式基本一致,这里分析一下虚拟线程设计与源码实现。
二. Platform Thread 与 Virtual Thread因为引入了虚拟线程,原来JDK存在java.lang.Thread类,俗称线程,为了更好地区分虚拟线程和原有的线程类,引入了一个全新类java.lang.VirtualThread(Thread类的一个子类型),直译过来就是”虚拟线程”。
题外话:在Loom项目早期规划里面,核心API其实命名为Fiber,直译过来就是”纤程”或者”协程”,后来成为了废案,在一些历史提交的Test类或者文档中还能看到类似于下面的代码:
123456789101112// java.lang.FiberFiber f = ...

RocketMQ主从同步原理
一. 主从同步概述主从同步这个概念相信大家在平时的工作中,多少都会听到。其目的主要是用于做一备份类操作,以及一些读写分离场景。比如我们常用的关系型数据库mysql,就有主从同步功能在。
主从同步,就是将主服务器上的数据同步到从服务器上,也就是相当于新增了一个副本。
而具体的主从同步的实现也各有千秋,如mysql中通过binlog实现主从同步,es中通过translog实现主从同步,redis中通过aof实现主从同步。那么,rocketmq又是如何实现的主从同步呢?
另外,主从同步需要考虑的问题是哪些呢?
数据同步的及时性?(延迟与一致性)
对主服务器的影响性?(可用性)
是否可替代主服务器?(可用性或者分区容忍性)
前面两个点是必须要考虑的,但对于第3个点,则可能不会被考虑。因为通过系统可能无法很好的做到这一点,所以很多系统就直接忽略这一点了,简单嘛。即很多时候只把从服务器当作是一个备份存在,不会接受写请求。如果要进行主从切换,必须要人工介入,做预知的有损切换。但随着技术的发展,现在已有非常多的自动切换主从的服务存在,这是在分布式系统满天下的当今的必然趋势。
二. RocketMQ ...
RocketMQ事务消息源码解析
RocketMQ提供了事务消息的功能,采用2PC(两阶段协议)+补偿机制(事务回查)的分布式事务功能,通过这种方式能达到分布式事务的最终一致。
一. 概述
半事务消息:指的是发送至broker但是还没被commit的消息,在半事务消息被确认之前都是无法被消费者消费的。
消息回查:由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,broker 通过扫描发现某条消息长期处于“半事务消息”时,需要主动向消息生产者询问该消息的最终状态(commit 或是 rollback),该询问过程即消息回查。
二. 交互流程
事务消息发送步骤如下:
发送方将半事务消息发送至broker。
broker将消息持久化成功之后,向发送方返回 Ack,确认消息已经发送成功,此时消息为半事务消息。
发送方开始执行本地事务逻辑。
发送方根据本地事务执行结果向服务端提交二次确认(commit 或是 rollback),服务端收到 commit 状态则将半事务消息标记为可投递,订阅方最终将收到该消息;服务端收到 rollback 状态则“删除”半事务消息,订阅方将不会接受该消息。
在断网或者 ...
RocketMQ消息过滤机制源码详解
RocketMQ提供了2种消息过滤的方式:
TAG 过滤
SQL92 过滤
SQL过滤默认是没有打开的,如果想要支持,必须在broker的配置文件中设置:enablePropertyFilter = true
一. 示例代码1.1 producer 代码1234567891011121314151617181920212223242526272829303132333435public class Producer { public static void main(String[] args) throws Exception { // 实例化消息生产者Producer DefaultMQProducer producer = new DefaultMQProducer("tag_p_g"); // 设置NameServer的地址 producer.setNamesrvAddr("127.0.0.1:9876"); produc ...
详解RocketMQ消息存储原理
本文基于RocketMQ 4.6.0进行源码分析
一. 存储概要设计RocketMQ存储的文件主要包括CommitLog文件、ConsumeQueue文件、Index文件。RocketMQ将所有topic的消息存储在同一个文件中,确保消息发送时按顺序写文件,尽最大的能力确保消息发送的高性能与高吞吐量。因为消息中间件一般是基于消息主题的订阅机制,所以给按照消息主题检索消息带来了极大的不便。为了提高消息消费的效率,RocketMQ引入了ConsumeQueue消息消费队列文件,每个topic包含多个消息消费队列,每一个消息队列有一个消息文件。Index索引文件的设计理念是为了加速消息的检索性能,根据消息的属性从CommitLog文件中快速检索消息。
CommitLog :消息存储文件,所有topic的消息都存储在CommitLog 文件中。
ConsumeQueue :消息消费队列,消息到达CommitLog 文件后,将异步转发到消息消费队列,供消息消费者消费。
IndexFile :消息索引文件,主要存储消息Key 与Offset 的对应关系。
1.1 CommitLog ...

MyBatisPlus + ShardingJDBC 批量插入不返回主键ID
本文讲述一个由 ShardingJDBC 使用不当引起的悲惨故事。
一. 问题重现有一天运营反馈我们部分订单状态和第三方订单状态无法同步。
根据现象找到了不能同步订单状态是因为 order 表的 thirdOrderId 为空导致的,但是这个字段为啥为空,排查过程比较波折。
过滤掉复杂的业务逻辑,当时的代码可以简化为这样:
12345678910111213141516171819202122Order order;// 业务在特定情况会生成新的订单if (特定条件) { order = buildOrders(); orderService.saveBatch(Lists.newArrayList(order));}// 省略复杂的业务逻辑// ...// 调用第三方下单ThirdOrder thirdOrder = callThirdPlaceOrder()// 设置order表 thirdOrderId 字段order.setThirdOrderId(thirdOrder.getOrderId());// 设置 order_item 表 thirdOrd ...

JVM Sandbox入门详解
一. 概述在日常开发中,经常会接触到面向AOP编程的思想,我们通常会使用Spring AOP来做统一的权限认证、异常捕获返回、日志记录等工作。之所以使用Spring AOP来实现上述功能,是因为这些场景本质上来说都是与业务场景挂钩的,但是具有一定的抽象程度,并且绝大多数业务逻辑类都已经被Spring容器托管了。但是这个世界上不是所有的Java应用都接入了Spring框架,接入Spring的应用也不是所有类都会被Spring容器托管,例如很多中间件代码、三方包代码,Java原生代码,都不能被Spring AOP代理到,所以在很多场景下Spring AOP都无法满足AOP编码的需求。
上面是从技术实现出发,说明了Spring AOP的局限性。如果从领域职责出发,像应用指标监控,全链路监控,故障定位,流量回放等与业务无关的场景代码放在业务系统中实现显然并不合适,此时如果有一种更为通用的AOP方式,将通用逻辑与业务逻辑解耦,岂不是美哉。
在 《JavaAgent详解》 中,我们提到了Java自身提供了JVM Instrumentation等功能,允许使用者以通过一系列API完成对JVM的复杂控 ...

工作面试老大难-MySQL中的锁类型
MySQL 是支持ACID特性的数据库。我们都知道”C”代表Consistent,当不同事务操作同一行记录时,为了保证一致性,需要对记录加锁。在MySQL 中,不同的引擎下的锁行为也会不同,本文将重点介绍 MySQL InnoDB引擎中常见的锁。
一. 准备1234567891011121314151617181920CREATE TABLE `user` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(32) DEFAULT NULL, `age` tinyint(4) DEFAULT '0', `phone` varchar(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_age` (`age`)) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4;create index test_age_index on user (age);#插入基础数据INSERT INTO `u ...

动态类型语言 VS 静态类型语言
一. 运行期动态修改类型结构动态编程语言是高级编程语言的一个类别,在计算机科学领域已被广泛应用。它是一类在运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。动态语言目前非常具有活力。众所周知的ECMAScript(JavaScript)便是一个动态语言,除此之外如PHP、Ruby、Python等也都属于动态语言,而C、C++、Java等语言则不属于动态语言。
例如下列 Python 代码:
1234567891011121314class Student(object): def __init__(self, name): self.name = nameif __name__ == '__main__': stu = Student("张三") stu.age = 18 # 运行时,给stu对象新增了一个age属性,但是在class声明时未声明该属性 def to_string(self): return f"Student ...

Arthas源码分析
一. 前言Arthas 相信大家已经不陌生了,肯定用过太多次了,平时说到 Arthas 的时候都知道是基于Java Agent的,那么他具体是怎么实现呢,今天就一起来看看。
首先 Arthas 是在 GitHub 开源的,我们可以直接去 GitHub 上获取源码:Arthas。
本文基于 Arthas 3.6.7 版本源码进行分析,具体源码注释可参考:bigcoder84/arthas
二. arthas源码调试在阅读源码的时候少不了需要对源码进行DEBUG,Arthas Debug 需要借助 IDEA 的远程Debug功能,具体可参考:
Debug Arthas In IDEA · Issue #222 · alibaba/arthas (github.com)
第一步:编写测试类
1234567891011121314public class Main { public static void main(String[] args) throws InterruptedException { int i = 0; ...