
Token 节省利器:Claude Agent Skills 使用与原理解析
Claude Agent Skills 以 “按需加载” 为核心,通过渐进式披露与双重上下文注入实现 token 高效利用,既解决了 LLM 领域专业化与上下文臃肿的矛盾,又支持开发者按规范快速创建自定义技能。本文聚焦其实际使用、自定义开发流程与底层技术原理,为开发者提供兼顾实用性与技术深度的实战指南。
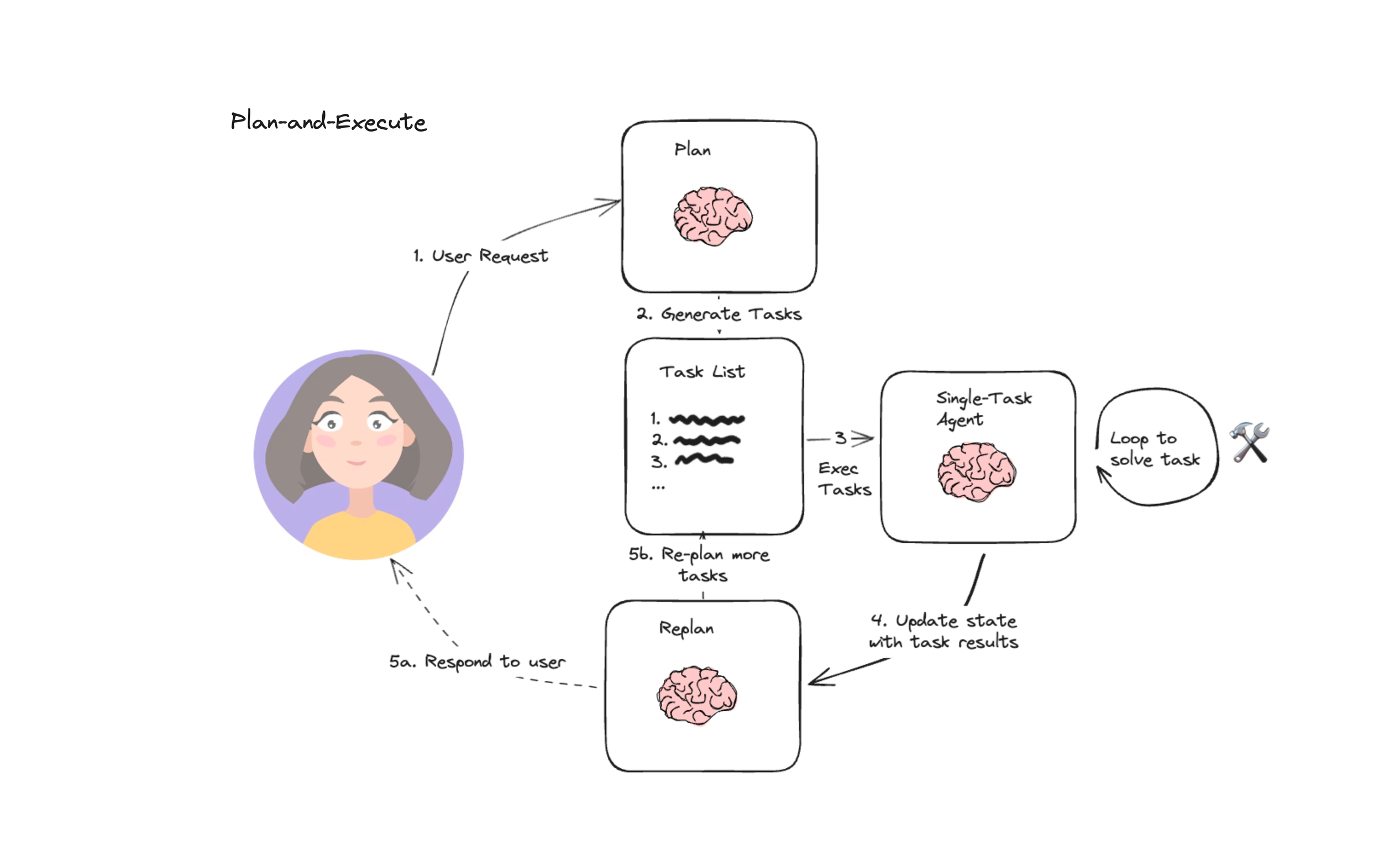
超越 ReAct:探寻Plan-And-Execute Agent的设计与实现原理
本文围绕 Plan-And-Execute 智能体展开系统解析,通过对比 ReAct 模式,阐明其在复杂任务中 “全局规划 + 动态调整” 的核心优势。文章依次拆解规划器、执行器、重新规划器、最终答案生成器四大核心组件的职责与协作逻辑,梳理 “规划 - 执行 - 整合” 的完整工作流程,并基于 LangChain 框架实现了从环境搭建、组件开发到全流程串联的实战案例,清晰呈现该类智能体的设计原理与落地细节,为复杂任务的智能处理提供了可行方案。
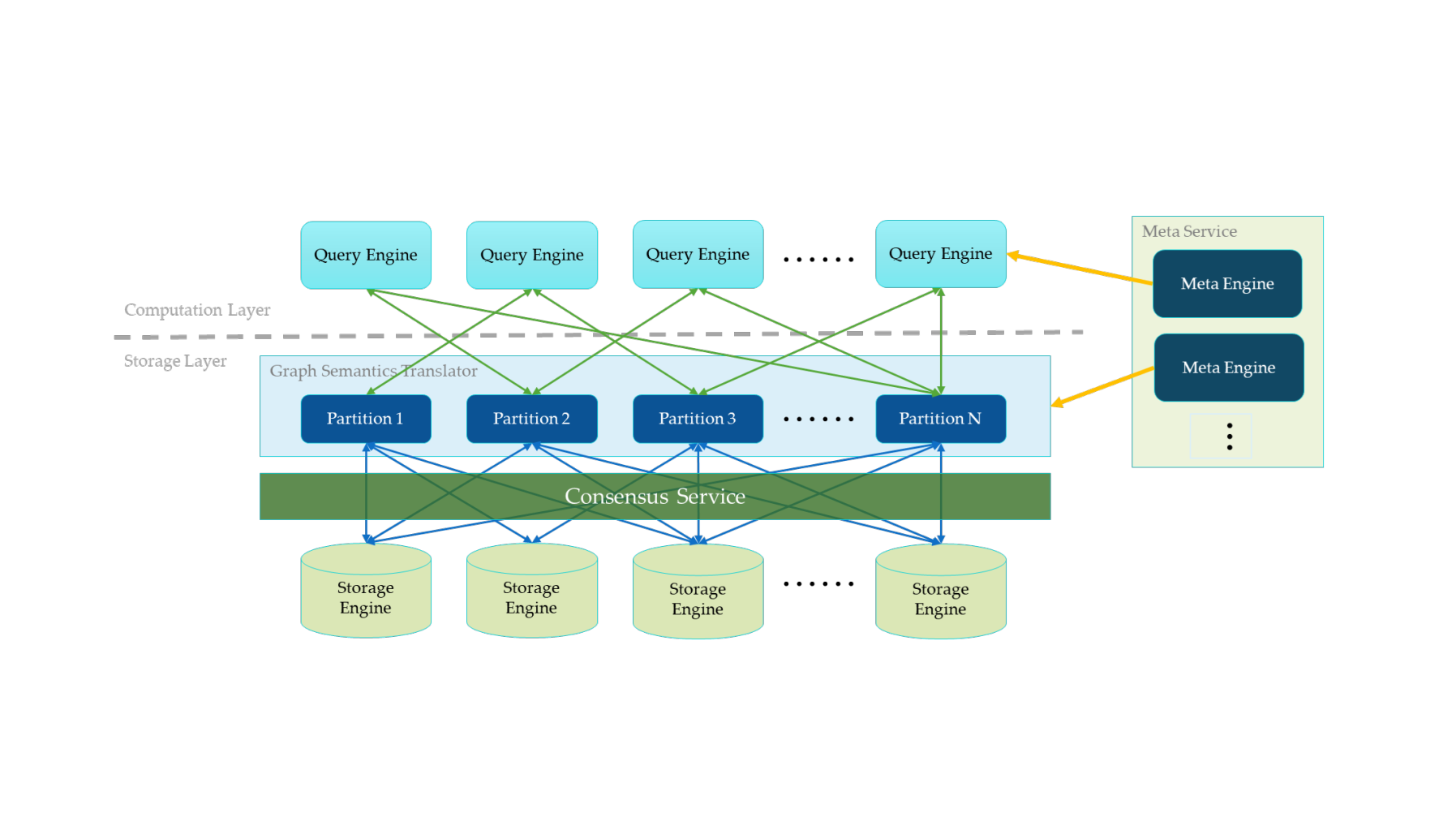
初探Nebula Graph核心架构设计
随着图数据在金融风控等场景的广泛应用,大规模关联数据的高效存储与低延迟查询成为核心需求,传统数据库难以兼顾超大规模与高并发查询的痛点日益凸显。Nebula Graph 作为分布式图数据库,采用 Meta Service、无状态计算层、Shared-nothing 存储层的三层架构,通过存算分离设计实现计算与存储资源的独立弹性伸缩。其核心技术包括以 Vertex ID 哈希分片的 Partition 机制、基于 RocksDB 的本地存储优化、图数据与 KV 结构的高效映射,以及 Raft 协议保障的多副本一致性。本文从整体架构、存储设计、查询流程及 Raft 同步原理等维度,梳理 Nebula Graph 的关键技术实现,为大规模图数据处理场景提供技术参考。
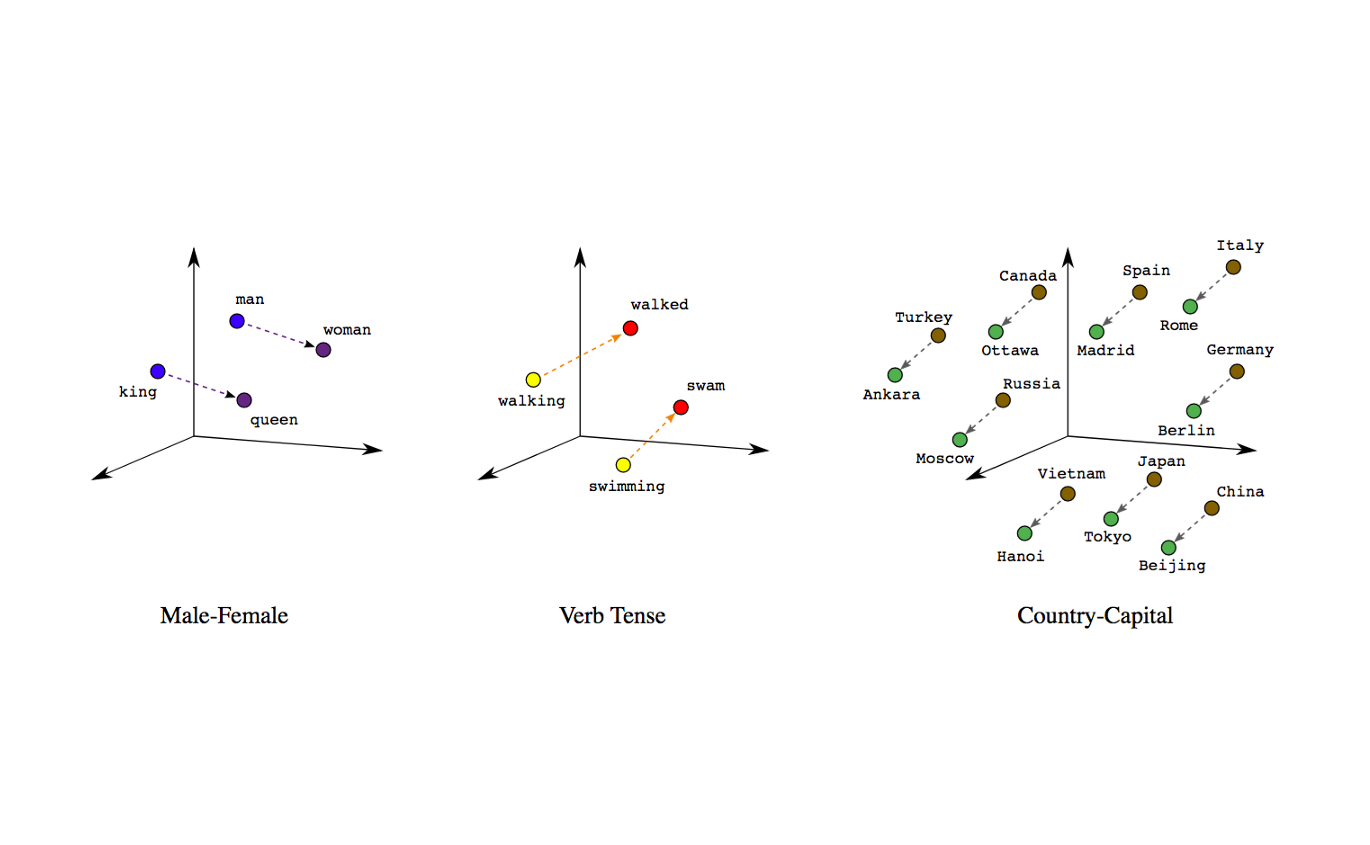
AI 如何“读懂”文字?词嵌入向量的底层逻辑、实现与可视化
词嵌入(Word Embedding)是大型语言模型(LLM)理解人类语言的核心基础,它解决了传统独热编码的维度爆炸、语义鸿沟等痛点,通过将离散单词映射为低维稠密向量,实现了对词汇语义和句法特征的精准捕捉。本文从语言表示的底层逻辑出发,系统梳理了词嵌入的技术演进:从 Word2Vec 的 CBOW 与 Skip-gram 模型、GloVe 的全局统计信息融合,到 FastText 的子词单元创新,再到现代 Transformer 架构中上下文相关的动态嵌入。结合阿里百炼平台的实战案例,通过词向量可视化、语义相似度计算等代码实现,直观展示了 “语义相似词在向量空间中距离相近” 的核心特性。同时,本文深入分析了词嵌入的优劣势,并揭示其在大模型中的关键作用 —— 作为语言理解的 “桥梁”,连接符号化文字与模型可处理的数值特征。无论你是 AI 技术学习者、大模型应用开发者,还是希望深入理解 LLM 底层机制的工程师,都能通过本文掌握词嵌入的核心原理、实践方法与工程价值,为后续 LLM 应用开发(如 LangChain 集成、语义检索等)奠定基础。

从函数到神经网络
积层是CNN的核心和灵魂,它的主要作用是自动从输入数据中提取特征。使用多个可学习的过滤器(卷积核) 在输入数据上滑动,检测局部区域内的特定模式(如边缘、角点、颜色、纹理等)。每个过滤器会生成一张特征图,记录了该过滤器所代表的特征在整个输入空间中的分布和强度
LLM 只会生成文本?用 ReAct 模式手搓一个简易 Claude Code Agent
在大语言模型(LLM)技术飞速发展的今天,单纯的文本生成能力已无法满足复杂任务的需求。Agent 作为一种能够自主决策、规划和执行任务的智能体,正在成为 LLM 落地应用的关键载体。而 ReAct 模式作为 Agent 领域的重要范式,通过 “思考 - 行动 - 观察” 的循环机制,极大地提升了 Agent 的逻辑性和任务解决能力。本文将从基础概念出发,逐步深入 ReAct 模式 Agent 的实现原理,并通过网页端模拟和代码实践,带大家从零构建一个最简单的 ReAct 模式 Agent。
一. 什么是 Agent在人工智能领域,Agent(智能体) 是指能够自主感知环境、做出决策并执行动作,以实现特定目标的实体。它并非单一的算法或模型,而是一个集成了 “感知 - 决策 - 执行” 能力的闭环系统。结合 LLM 技术的 Agent,核心特征可概括为以下三点:
自主性(Autonomy):无需人类持续干预,能根据任务目标自主规划步骤。例如,当用户提出 “整理近 3 个月的销售数据并生成可视化报告” 时,Agent 可自主决定 “获取数据→清洗数据→分析数据→生成图表” ...

一篇文章搞懂G1垃圾回收器
一. 概述在 G1 垃圾回收器正式引入前,CMS(Concurrent Mark Sweep,并发标记清除)作为 JVM 中主流的垃圾回收器,虽凭借 “低停顿” 特性在互联网、电商等对响应时间敏感的场景中广泛应用,但随着应用规模扩大和内存需求提升,其设计层面的缺陷逐渐暴露,成为影响系统稳定性和性能的关键瓶颈:
内存碎片问题严重,触发 Full GC 风险高:CMS 的 “清除” 阶段采用标记 - 清除(Mark-Sweep)算法,而非标记 - 整理(Mark-Compact)算法 —— 这意味着它在回收无用对象后,仅会标记出内存中的空闲区域,不会对存活对象进行移动和整理。随着垃圾回收次数增加,内存空间会逐渐被分割成大量不连续的 “碎片”,这些碎片虽然总容量可能满足对象分配需求,但由于单个碎片的空间小于待分配对象的大小,导致新对象无法正常分配,最终触发Full GC。Full GC 会暂停所有用户线程(STW,Stop-The-World),并采用 Serial Old 回收器进行内存整理,其停顿时间通常达到数百毫秒甚至数秒,对于每秒处理数千笔交易的电商系统、实时通信平台等场景,这种级 ...

手把手带你从零到一实现一个MCP Server
最近 AI 领域的 MCP(模型上下文协议)特别火,它是 Anthropic 推出的开放标准,给大语言模型和 AI 助手提供了统一接口,让 AI 能调用外部工具完成复杂任务。今天咱们就来带大家看看,如何通过 MCP 实现本地 Excel 文件的读取和写入,并且基于 Spring AI 框架进行开发。
Spring State Machine入门实践
一. 状态机1.1 什么是状态先来解释什么是状态( State )。现实事物是有不同状态的,例如一个自动门,就有 open 和 closed 两种状态。我们通常所说的状态机是有限状态机,也就是被描述的事物的状态的数量是有限个,例如自动门的状态就是两个 open 和 closed 。
状态机,也就是 State Machine ,不是指一台实际机器,而是指一个数学模型。说白了,一般就是指一张状态转换图。
状态机的全称是有限状态自动机,自动两个字也是包含重要含义的。给定一个状态机,同时给定它的当前状态以及输入,那么输出状态时可以明确的运算出来的。例如对于自动门,给定初始状态 closed ,给定输入“开门”,那么下一个状态时可以运算出来的。
1.2 状态机中的概念下面来给出状态机的四大概念:
State:状态,一个状态机至少要包含两个状态。
Event:事件,事件就是执行某个操作的触发条件或者口令。对于自动门,“按开门按钮”就是一个事件。
Action:动作,事件发生以后要执行动作。例如事件是“按开门按钮”,动作是“开门”。编程的时候,一个 Action一般就对应一个函数。
Transi ...

深入剖析缓存一致性问题:延时双删的利弊与替代方案
在当今的分布式系统架构中,缓存凭借其快速的数据读取能力,成为提升系统性能和响应速度的关键组件。然而,缓存的引入也带来了缓存一致性问题,这一问题成为开发者在系统设计与维护中必须攻克的难关。缓存一致性问题聚焦于数据更新时,如何确保数据库和缓存中的数据始终保持同步,一旦处理不当,数据不一致的情况就会出现,进而引发各类难以排查和修复的系统故障。
一. 缓存一致性问题的常见场景在实际的系统运行中,缓存一致性问题主要集中在数据更新操作阶段。当数据库中的数据发生变动,缓存中的对应数据也需要及时更新,以保证数据的一致性。常见的读写场景如下:
读操作流程:系统首先尝试从缓存中读取数据。若缓存中存在所需数据,直接返回;若缓存未命中,则从数据库中读取数据,并将读取到的数据存入缓存,以便后续读取操作能够更快响应。
写操作流程:一般的做法是先更新数据库,然后再更新缓存。但如果在更新数据库之后、更新缓存之前出现异常情况,比如系统崩溃、网络中断等,就会导致数据库和缓存中的数据不一致,数据库已更新为新数据,而缓存中仍保留着旧数据。
二. 单次删除在并发场景下的问题在缓存一致性问题的解决思路中,简单的单 ...