本文所涉及的注释源码:bigcoder84/dledger
RocketMQ 4.5版本之前,可以采用主从架构进行集群部署,但是如果 master 节点挂掉,不能自动在集群中选举出新的 master 节点,需要人工介入,在4.5版本之后提供了 DLedger 模式,DLedger 是 Open Messaging 发布的一个基于 Raft 协议实现的Java类库,可以方便引用到系统中,满足其高可用、高可靠、强一致的需求,其中在 RocketMQ 中作为消息 Broker 存储高可用实现的一种解决方案。使用Raft算法,如果 master 节点出现故障,可以自动选举出新的 master 进行切换。
在阅读本文之前,建议先仔细了解Raft协议的思路,具体可移步至:深度解析 Raft 分布式一致性协议
一. Raft协议概述 在分布式系统应用中,高可用、一致性是经常面临的问题,针对不同的应用场景,我们会选择不同的架构方式,比如master-slave、基于ZooKeeper 选主。随着时间的推移,出现了基于Raft算法自动选主的方式,Raft 是在 Paxos 的基础上,做了一些简化和限制,大大简化了算法的复杂度。Raft协议是目前分布式领域一个非常重要的一致性协议,RocketMQ 的主从切换机制也是介于Raft协议实现的。Raft 协议主要包含两个部分:Leader选举和日志复制。
1.1 Leader选举 Raft协议的核心思想是在一个复制组内选举一个Leader节点,后续统一由Leader节点处理客户端的读写请求,从节点只是从Leader节点复制数据,即一个复制组在接收客户端的读写请求之前,要先从复制组中选择一个Leader节点,这个过程称为Leader选举。
Raft协议的选举过程如下:
各个节点的初始状态为Follower,每个节点会设置一个计时器,每个节点的计时时间是150~300ms的一个随机值。
节点的计时器到期后,状态会从Follower变更为Candidate, 进入该状态的节点会发起一轮投票,首先为自己投上一票,然后向集群中的其他节点发起“拉票”,期待得到超过半数的选票支持。
当集群内的节点收到投票请求后,如果该节点本轮未进行投票,则投赞成票,否则投反对票,然后返回结果并重置计时器继续倒数计时。如果计算器到期,则状态会由Follower变更为Candidate。
当集群内的节点收到投票请求后,如果该节点本轮未进行投票,则投赞成票,否则投反对票,然后返回结果并重置计时器继续倒数计时。如果计算器到期,则状态会由Follower变更为Candidate。
主节点会定时向集群内的所有从节点发送心跳包。从节点在收到心跳包后重置计时器,这是主节点维持其“统治地位”的手段。因为从节点一旦计时器到期,就会从Follower变更为Candidate,以此来尝试发起新一轮选举。
Raft是一个分布式领域的一致性协议,只是一个方法论,需要使用者根据协议描述通过编程语言具体实现。
1.2 日志复制 客户端向DLedger集群发起一个写数据请求,Leader节点收到写请求后先将数据存入Leader节点,然后将数据广播给它所有的从节点。从节点收到Leader节点的数据推送后对数据进行存储,然后向主节点汇报存储的结果。Leader节点会对该日志的存储结果进行仲裁,如果超过集群数量的一半都成功存储了该数据,则向客户端返回写入成功,否则向客户端返回写入失败。
本文主要分析 DLedger 中 Leader 选举的原理,日志复制模块可移步至:
二. DLedger概述 2.1 DLedger是什么 DLedger 定位是一个工业级的 Java Library,可以友好地嵌入各类 Java 系统中,满足其高可用、高可靠、强一致的需求,和这一定位比较接近的是 Ratis 。
Ratis 是一个典型的”日志 + 状态机”的实现,虽然其状态机可以自定义,却仍然不满足消息领域的需求。 在消息领域,如果根据日志再去构建“消息状态机”,就会产生 Double IO 的问题,造成极大的资源浪费,因此,在消息领域,是不需要状态机的,日志和消息应该是合二为一。
DLedger 的纯粹日志写入和读出,使其精简而健壮,总代码不超过4000行,测试覆盖率高达70%。而且这种原子化的设计,使其不仅可以充分适应消息系统,也可以基于这些日志去构建自己的状态机,从而适应更广泛的场景。
综上所述,DLedger 是一个基于 Raft 实现的、高可靠、高可用、强一致的 Commitlog 存储 Library。
DLedger 的实现大体可以分为以下两个部分:
1.选举 Leader
2.复制日志
其整体架构如下图:
后文我们将详细介绍 DLedger 的实现细节以及它是如何整合进RocketMQ中使得RocketMQ集群也能拥有分布式强一致性集群模式。
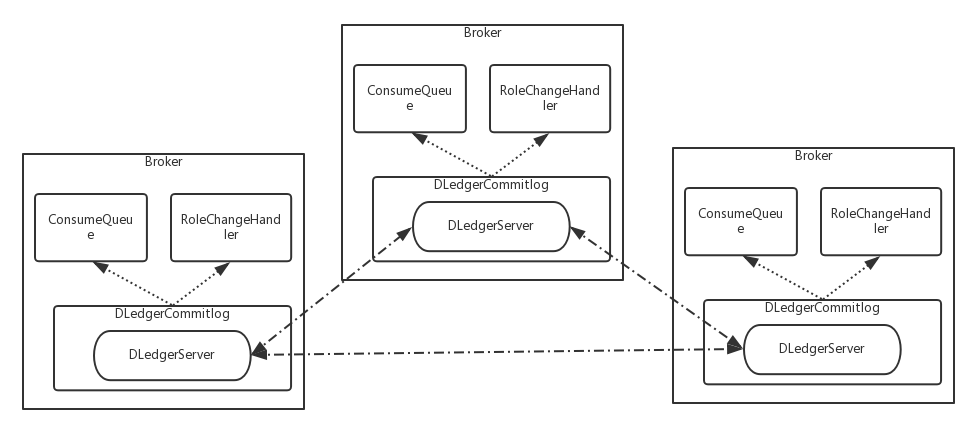
2.2 DLedger应用 在 Apache RocketMQ 中,DLedger 不仅被直接用来当做消息存储,也被用来实现一个嵌入式的 KV 系统,以存储元数据信息。
2.2.1 DLedger 作为 RocketMQ 的消息存储
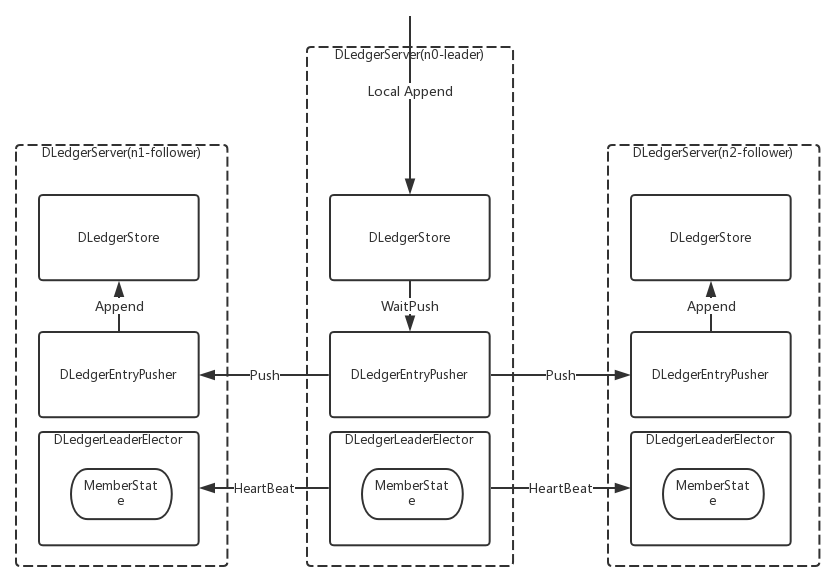
DLedgerCommitlog 用来代替现有的 Commitlog 存储实际消息内容,它通过包装一个 DLedgerServer 来实现复制;
依靠 DLedger 的直接存取日志的特点,消费消息时,直接从 DLedger 读取日志内容作为消息返回给客户端;
依靠 DLedger 的 Raft 选举功能,通过 RoleChangeHandler 把角色变更透传给 RocketMQ 的Broker,从而达到主备自动切换的目标;
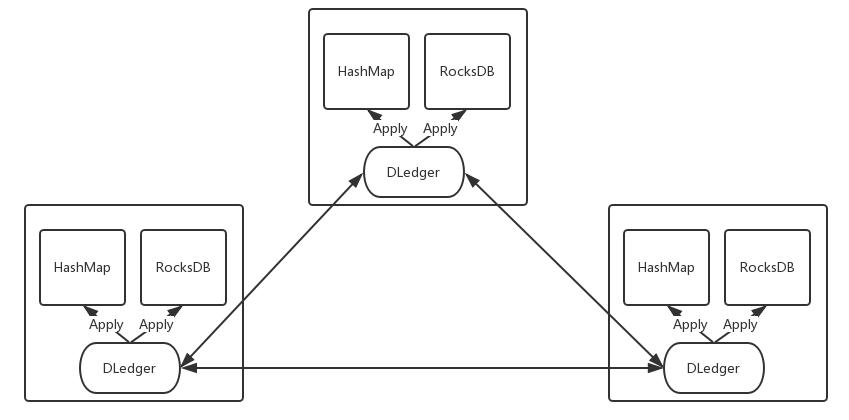
2.2.2 利用 DLedger 实现一个高可用的嵌入式 KV 存储
DLedger 用来存储 KV 的增删改日志;
通过将日志一条条 Apply 到本地 Map,比如 HashMap 或者 第三方 的 RocksDB等;
三. RocketMQ DLedger Leader选举流程 RocketMQ 实现Raft协议Leader选举,其代码并不在 RocketMQ 工程中,而是在 openmessaging 标准中。
代码仓库:openmessaging/dledger
DLedger选主模块中主要涉及如下类:
DLedgerConfig:主从切换模块相关的配置信息
DLedgerClientProtocol:DLedger客户端协议。
DLedgerRaftProtocol:DLedger Raft协议。
DLedgerClientProtocolHandler:DLedger客户端协议处理器。
DLedgerProtocolHandler:DLedger服务端协议处理器。
DLedgerRpcService:DLedger节点之前的网络通信,默认基于Netty实现,默认实现类为DLedgerRpcNettyService。
DLedgerLeaderElector:基于Raft协议的Leader选举类(重点)。
DLedgerServer:基于Raft协议的集群内节点的封装类。
3.1 DLedgerLeaderElector核心类及核心属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 public class DLedgerLeaderElector { private static final Logger LOGGER = LoggerFactory.getLogger(DLedgerLeaderElector.class); private final Random random = new Random (); private final DLedgerConfig dLedgerConfig; private final MemberState memberState; private final DLedgerRpcService dLedgerRpcService; private volatile long lastLeaderHeartBeatTime = -1 ; private volatile long lastSendHeartBeatTime = -1 ; private volatile long lastSuccHeartBeatTime = -1 ; private int heartBeatTimeIntervalMs = 2000 ; private int maxHeartBeatLeak = 3 ; private long nextTimeToRequestVote = -1 ; private volatile boolean needIncreaseTermImmediately = false ; private int minVoteIntervalMs = 300 ; private int maxVoteIntervalMs = 1000 ; private final List<RoleChangeHandler> roleChangeHandlers = new ArrayList <>(); private VoteResponse.ParseResult lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE; private long lastVoteCost = 0L ; private final StateMaintainer stateMaintainer; private final TakeLeadershipTask takeLeadershipTask = new TakeLeadershipTask (); }
3.2 选举状态管理器初始化 通过DLedgerLeaderElector的startup()方法启动状态管理机:
1 2 3 4 5 6 7 8 9 10 11 12 public void startup () { stateMaintainer.start(); for (RoleChangeHandler roleChangeHandler : roleChangeHandlers) { roleChangeHandler.startup(); } }
实现关键点如下:
stateMaintainer是Leader选举内部维护的状态机,即维护节点状态在Follower、Candidate、Leader之间转换,需要先调用其start()方法启动状态机。
依次启动注册的角色转换监听器,即内部状态机的状态发生变更后的事件监听器,是Leader选举的功能扩展点。
StateMaintainer的父类为ShutdownAbleThread,继承自Thread,故调用其start()方法最终会调用run()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Override public void run () { while (running.get()) { try { doWork(); } catch (Throwable t) { if (logger != null ) { logger.error("Unexpected Error in running {} " , getName(), t); } } } latch.countDown(); }
StateMaintainer状态机的实现要点就是 “无限死循环”调用doWork()方法,直到该状态机被关闭。doWork() 方法在 ShutdownAbleThread 被声明为抽象方法,具体由各个子类实现,我们将目光投向StateMaintainer的doWork()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class StateMaintainer extends ShutdownAbleThread { public StateMaintainer (String name, Logger logger) { super (name, logger); } @Override public void doWork () { try { if (DLedgerLeaderElector.this .dLedgerConfig.isEnableLeaderElector()) { DLedgerLeaderElector.this .refreshIntervals(dLedgerConfig); DLedgerLeaderElector.this .maintainState(); } sleep(10 ); } catch (Throwable t) { DLedgerLeaderElector.LOGGER.error("Error in heartbeat" , t); } } }
如果当前节点参与Leader选举,则调用maintainState()方法驱动状态机,并且每一次驱动状态机后休息10ms。
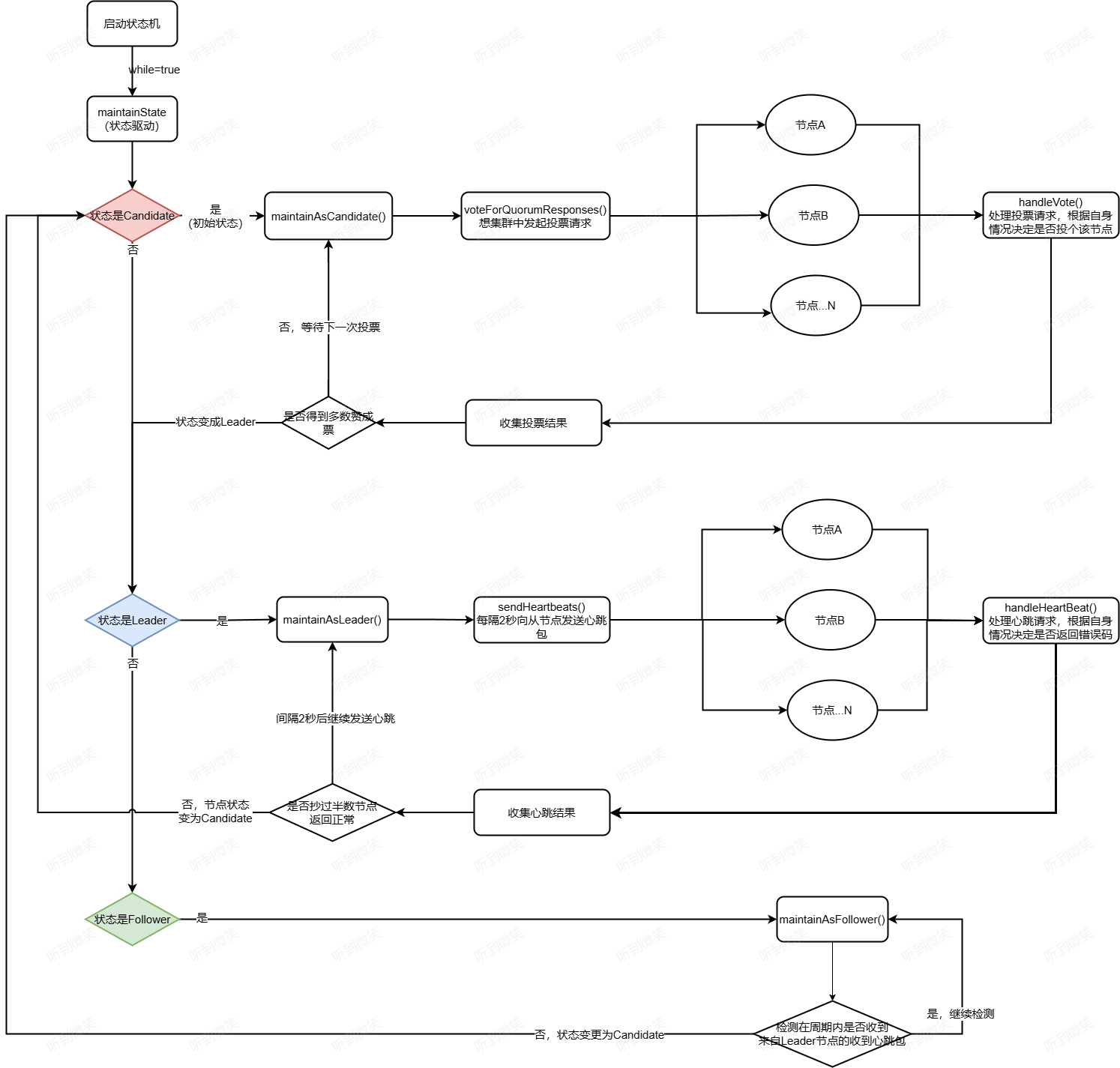
1 2 3 4 5 6 7 8 9 10 11 12 13 private void maintainState () throws Exception { if (memberState.isLeader()) { maintainAsLeader(); } else if (memberState.isFollower()) { maintainAsFollower(); } else { maintainAsCandidate(); } }
状态机的驱动实现思路比较简单,就是根据状态机当前状态对应的方法,在该状态下检测状态机是否满足状态变更的条件,如果满足则变更状态。接下来对上述3个方法进行详细介绍,帮助读者理解节点在各个状态时需要处理的核心逻辑。为便于理解,先给出在3个状态下需要处理的核心逻辑点。
Leader:领导者、主节点,该状态下需要定时向从节点发送心跳包,用于传播数据、确保其领导地位。
Follower:从节点,该状态下会开启定时器,尝试进入Candidate状态,以便发起投票选举,一旦收到主节点的心跳包,则重置定时器。
Candidate:候选者,该状态下的节点会发起投票,尝试选择自己为主节点,选举成功后,不会存在该状态下的节点。
3.3 选举状态机状态流转 MemberState的初始化,发现其初始状态为Candidate。接下来深入学习maintainAsCandidate()方法,以此探究实现原理。
3.3.1 maintainAsCandidate 根据状态机的流转代码可知,当集群中节点的状态为Candidate时会执行该方法,处于该状态的节点会发起投票请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (System.currentTimeMillis() < nextTimeToRequestVote && !needIncreaseTermImmediately) { return ; } long term;long ledgerEndTerm;long ledgerEndIndex;if (!memberState.isCandidate()) { return ; }
第一步,先介绍几个变量的含义。
long nextTimeToRequestVote:下一次可发起投票的时间,如果当前时间小于该值,说明计时器未过期,此时无须发起投票。
long needIncreaseTermImmediately:是否应该立即发起投票。如果为true,则忽略计时器,该值默认为false。作用是在从节点收到主节点的心跳包,并且当前状态机的轮次大于主节点轮次(说明 集群中Leader的投票轮次小于从节点的轮次)时,立即发起新的投票 请求。
long term:投票轮次。
long ledgerEndTerm:Leader节点当前的投票轮次。
long ledgerEndIndex:当前节点日志的最大序列号,即下一条日志的开始index。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 synchronized (memberState) { if (!memberState.isCandidate()) { return ; } if (lastParseResult == VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT || needIncreaseTermImmediately) { long prevTerm = memberState.currTerm(); term = memberState.nextTerm(); LOGGER.info("{}_[INCREASE_TERM] from {} to {}" , memberState.getSelfId(), prevTerm, term); lastParseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE; } else { term = memberState.currTerm(); } ledgerEndIndex = memberState.getLedgerEndIndex(); ledgerEndTerm = memberState.getLedgerEndTerm(); }
第二步:初始化team、ledgerEndIndex、ledgerEndTerm属性,其实现关键点如下:
投票轮次的初始化机制:如果上一次的投票结果为WAIT_TO_VOTE_NEXT(等待下一轮投票)或应该立即发起投票,则通过状态机获取新一轮投票的序号,默认在当前轮次递增1,并将lastParseResult更新为WAIT_TO_REVOTE(等待投票)。
如果上一次的投票结果不是WAIT_TO_VOTE_NEXT,则投票轮次依然为状态机内部维护的投票轮次。
1 2 3 4 5 6 7 8 9 10 if (needIncreaseTermImmediately) { nextTimeToRequestVote = getNextTimeToRequestVote(); needIncreaseTermImmediately = false ; return ; }
第三步:如果 needIncreaseTermImmediately 为 true,则重置该标记位为 false,并重新设置下一次投票超时时间,其实现逻辑为当前时间戳+上次投票的开销+最小投票间隔之间的随机值,这里是Raft协议 的一个关键点,即每个节点的投票超时时间引入了随机值。
1 2 3 4 final List<CompletableFuture<VoteResponse>> quorumVoteResponses = voteForQuorumResponses(term, ledgerEndTerm, ledgerEndIndex);
第四步:向集群内的其他节点发起投票请求,并等待各个节点的响应结果。在这里我们先将其当作黑盒,详细过程我们在后文阐述。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 final AtomicLong knownMaxTermInGroup = new AtomicLong (term);final AtomicInteger allNum = new AtomicInteger (0 );final AtomicInteger validNum = new AtomicInteger (0 );final AtomicInteger acceptedNum = new AtomicInteger (0 );final AtomicInteger notReadyTermNum = new AtomicInteger (0 );final AtomicInteger biggerLedgerNum = new AtomicInteger (0 );final AtomicBoolean alreadyHasLeader = new AtomicBoolean (false );
在进行投票结果仲裁之前,先介绍几个局部变量的含义:
knownMaxTermInGroup:已知的最大投票轮次
allNum:所有投票数
validNum:有效投票数
acceptedNum:赞成票数量
notReadyTermNum:未准备投票的节点数量,如果对端节点的投票轮次小于发起投票的轮次,则认为对端未准备好,对端节点使用本轮次进入Candidate状态。
biggerLedgerNum:发起投票的节点的ledgerEndTerm小于对端节点的个数
alreadyHasLeader:是否已经存在Leader
上述变量值都来自当前节点向集群内其他节点发送投票请求的响应结果,即投票与响应投票。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 CountDownLatch voteLatch = new CountDownLatch (1 );for (CompletableFuture<VoteResponse> future : quorumVoteResponses) { future.whenComplete((VoteResponse x, Throwable ex) -> { try { if (ex != null ) { throw ex; } LOGGER.info("[{}][GetVoteResponse] {}" , memberState.getSelfId(), JSON.toJSONString(x)); if (x.getVoteResult() != VoteResponse.RESULT.UNKNOWN) { validNum.incrementAndGet(); } synchronized (knownMaxTermInGroup) { switch (x.getVoteResult()) { case ACCEPT: acceptedNum.incrementAndGet(); break ; case REJECT_ALREADY_HAS_LEADER: alreadyHasLeader.compareAndSet(false , true ); break ; case REJECT_TERM_SMALL_THAN_LEDGER: case REJECT_EXPIRED_VOTE_TERM: if (x.getTerm() > knownMaxTermInGroup.get()) { knownMaxTermInGroup.set(x.getTerm()); } break ; case REJECT_EXPIRED_LEDGER_TERM: case REJECT_SMALL_LEDGER_END_INDEX: biggerLedgerNum.incrementAndGet(); break ; case REJECT_TERM_NOT_READY: notReadyTermNum.incrementAndGet(); break ; case REJECT_ALREADY_VOTED: case REJECT_TAKING_LEADERSHIP: default : break ; } } if (alreadyHasLeader.get() || memberState.isQuorum(acceptedNum.get()) || memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) { voteLatch.countDown(); } } catch (Throwable t) { LOGGER.error("vote response failed" , t); } finally { allNum.incrementAndGet(); if (allNum.get() == memberState.peerSize()) { voteLatch.countDown(); } } }); }
第五步:统计投票结果,后续会根据投票结果决定是否可以成为Leader,从而决定当前节点的状态,具体实现逻辑如下:
ACCEPT:赞成票(acceptedNum)加1,只有得到的赞成票超过集群节点数量的一半才能成为Leader。
REJECT_ALREADY_HAS_LEADER:拒绝票,原因是集群中已经存在Leaer节点了。alreadyHasLeader设置为true,无须再判断其他投票结果了,结束本轮投票。
REJECT_TERM_SMALL_THAN_LEDGER:拒绝票,原因是自己维护的term小于远端维护的ledgerEndTerm。如果对端的 term 大于自己的 term,需要记录对端最大的投票轮次,以便更新自己的投票轮次。
REJECT_EXPIRED_VOTE_TERM:拒绝票,原因是自己维护的投票轮次小于远端维护的投票轮次,并且更新自己维护的投票轮次。
REJECT_EXPIRED_LEDGER_TERM:拒绝票,原因是自己维护的 ledgerTerm 小于对端维护的 ledgerTerm ,此种情况下需要增加计数器biggerLedgerNum的值。
REJECT_SMALL_LEDGER_END_INDEX:拒绝票,原因是对端的ledgerTeam与自己维护的ledgerTeam相等,但自己维护的dedgerEndIndex小于对端维护的值,这种情况下需要增加biggerLedgerNum计数器的值。
REJECT_TERM_NOT_READY:拒绝票,原因是对端的投票轮次小于自己的投票轮次,即对端还未准备好投票。此时对端节点使用自己的投票轮次进入Candidate状态。
REJECT_ALREADY_VOTED:拒绝票,原因是已经投给了其他节点。
REJECT_TAKING_LEADERSHIP:拒绝票,原因是对端的投票轮次和自己相等,但是对端节点的ledgerEndIndex比自己的ledgerEndIndex大,这意味着对端节点的日志比自己更新。Raft协议中规定,节点不能将自己手中票额投给比自己日志落后的节点。
每个 candidate 必须在 RequestVote RPC 中携带自己本地日志的最新 (term, index),如果 follower 发现这个 candidate 的日志还没有自己的新,则拒绝投票给该 candidate 。
Candidate 想要赢得选举成为 leader,必须得到集群大多数节点的投票,那么它的日志就一定至少不落后于大多数节点 。又因为一条日志只有复制到了大多数节点才能被 commit,因此能赢得选举的 candidate 一定拥有所有 committed 日志 。
1 2 3 4 5 6 7 try { voteLatch.await(2000 + random.nextInt(maxVoteIntervalMs), TimeUnit.MILLISECONDS); } catch (Throwable ignore) { }
第六步:前面在获取投票响应时是在CompletableFuture.whenComplete中实现的,统计过程是异步完成的,所以这里需要等待投票结果统计完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 lastVoteCost = DLedgerUtils.elapsed(startVoteTimeMs); VoteResponse.ParseResult parseResult; if (knownMaxTermInGroup.get() > term) { parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT; nextTimeToRequestVote = getNextTimeToRequestVote(); changeRoleToCandidate(knownMaxTermInGroup.get()); } else if (alreadyHasLeader.get()) { parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE; nextTimeToRequestVote = getNextTimeToRequestVote() + (long ) heartBeatTimeIntervalMs * maxHeartBeatLeak; } else if (!memberState.isQuorum(validNum.get())) { parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE; nextTimeToRequestVote = getNextTimeToRequestVote(); } else if (!memberState.isQuorum(validNum.get() - biggerLedgerNum.get())) { parseResult = VoteResponse.ParseResult.WAIT_TO_REVOTE; nextTimeToRequestVote = getNextTimeToRequestVote() + maxVoteIntervalMs; } else if (memberState.isQuorum(acceptedNum.get())) { parseResult = VoteResponse.ParseResult.PASSED; } else if (memberState.isQuorum(acceptedNum.get() + notReadyTermNum.get())) { parseResult = VoteResponse.ParseResult.REVOTE_IMMEDIATELY; } else { parseResult = VoteResponse.ParseResult.WAIT_TO_VOTE_NEXT; nextTimeToRequestVote = getNextTimeToRequestVote(); } lastParseResult = parseResult; LOGGER.info("[{}] [PARSE_VOTE_RESULT] cost={} term={} memberNum={} allNum={} acceptedNum={} notReadyTermNum={} biggerLedgerNum={} alreadyHasLeader={} maxTerm={} result={}" , memberState.getSelfId(), lastVoteCost, term, memberState.peerSize(), allNum, acceptedNum, notReadyTermNum, biggerLedgerNum, alreadyHasLeader, knownMaxTermInGroup.get(), parseResult); if (parseResult == VoteResponse.ParseResult.PASSED) { LOGGER.info("[{}] [VOTE_RESULT] has been elected to be the leader in term {}" , memberState.getSelfId(), term); changeRoleToLeader(term); }
第七步:根据投票结果进行仲裁,从而驱动状态机:
如果对端的投票轮次大于当前节点维护的投票轮次,则先重置投票计时器,然后在定时器到期后使用对端的投票轮次重新进入Candidate状态。
如果集群内已经存在Leader节点,当前节点将继续保持 Candidate 状态,重置计时器,但这个计时器还需要增加 heartBeatTimeIntervalMs*maxHeartBeatLeak,其中 heartBeatTimeIntervalMs 为一次心跳间隔时间,maxHeartBeatLeak为允许丢失的最大心跳包。增加这个时间是因为集群内既然已经存在Leader节点了,就会在一个心跳周期内发送心跳包,从节点在收到心跳包后会重置定时器,即阻止Follower节点进入Candidate状态。这样做的目的是在指定时间内收到Leader节点的心跳包,从而驱动当前节点的状态由Candidate向Follower转换
如果收到的有效票数未超过半数,则重置计时器并等待重新投票,注意当前状态为WAIT_TO_REVOTE,该状态下的特征是下次投票时不增加投票轮次。
如果得到的赞同票超过半数,则成为Leader节点。
如果得到的赞成票加上未准备好投票的节点数超过半数,则立即发起投票,故其结果为REVOTE_IMMEDIATELY,因为此处没有更新 nextTimeToRequestVote 字段,所以下次进入循环又会进入投票逻辑。
maintainAsCandidate()方法的流程就介绍到这里了,下面介绍maintainAsLeader()方法。
3.3.2 maintainAsLeader 经过 maintainAsCandidate 投票选举被其他节点选举为Leader后, 在该状态下会执行maintainAsLeader()方法,其他节点的状态还是Candidate,并在计时器过期后,又尝试发起选举。接下来重点分析成为Leader节点后,该节点会做些什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private void maintainAsLeader () throws Exception { if (DLedgerUtils.elapsed(lastSendHeartBeatTime) > heartBeatTimeIntervalMs) { long term; String leaderId; synchronized (memberState) { if (!memberState.isLeader()) { return ; } term = memberState.currTerm(); leaderId = memberState.getLeaderId(); lastSendHeartBeatTime = System.currentTimeMillis(); } sendHeartbeats(term, leaderId); } }
Leader状态的节点主要按固定频率向集群内的其他节点发送心跳包,实现细节如下:
如果当前时间与上一次发送心跳包的间隔时间大于一个心跳包周期(默认为2s),则进入心跳包发送处理逻辑,否则忽略。
如果当前状态机的状态已经不是Leader,则忽略。
记录本次发送心跳包的时间戳。
调用sendHeartbeats()方法向集群内的从节点发送心跳包。该方法我们在后文详细介绍。
3.3.3 maintainAsFollower Candidate状态的节点在收到Leader节点发送的心跳包后,状态变更为Follower,我们先来看在Follower状态下,节点会做些什么:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void maintainAsFollower () { if (DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > 2L * heartBeatTimeIntervalMs) { synchronized (memberState) { if (memberState.isFollower() && DLedgerUtils.elapsed(lastLeaderHeartBeatTime) > (long ) maxHeartBeatLeak * heartBeatTimeIntervalMs) { LOGGER.info("[{}][HeartBeatTimeOut] lastLeaderHeartBeatTime: {} heartBeatTimeIntervalMs: {} lastLeader={}" , memberState.getSelfId(), new Timestamp (lastLeaderHeartBeatTime), heartBeatTimeIntervalMs, memberState.getLeaderId()); changeRoleToCandidate(memberState.currTerm()); } } } }
如果节点在maxHeartBeatLeak个心跳包(默认为3个)周期内未收到心跳包,则将状态变更为Candidate。从这里也不得不佩服RocketMQ 在性能方面如此追求极致,即在不加锁的情况下判断是否超过了2个心跳包周期,减少加锁次数,提高性能。
上面3个方法就是状态机在当前状态下执行的处理逻辑,主要是结合当前实际的运行情况将状态机进行驱动,例如调用changeRoleToCandidate() 方法将自身状态变更为 Candidate,调用 changeRoleToLeader() 方法将状态变更为 Leader,调用 changeRoleToFollower() 方法将状态变更为 Follower。这3个方法的实现类似,接下来以 changeRoleToLeader() 方法为例进行讲解。
3.3.4 changeRoleToLeader 当状态机从Candidate状态变更为Leader节点后会调用该方法,即当处于Candidate状态的节点在得到集群内超过半数节点的支持后将进入该状态,我们来看该方法的实现细节:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void changeRoleToLeader (long term) { synchronized (memberState) { if (memberState.currTerm() == term) { memberState.changeToLeader(term); lastSendHeartBeatTime = -1 ; handleRoleChange(term, MemberState.Role.LEADER); LOGGER.info("[{}] [ChangeRoleToLeader] from term: {} and currTerm: {}" , memberState.getSelfId(), term, memberState.currTerm()); } else { LOGGER.warn("[{}] skip to be the leader in term: {}, but currTerm is: {}" , memberState.getSelfId(), term, memberState.currTerm()); } } }
首先更新状态机(MemberState)的角色为Leader,并设置leaderId为当前节点的ID,然后调用 handleRoleChange 方法触发角色状态转换事件,从而执行扩展点的逻辑代码。
选举状态机状态的流转就介绍到这里,在上面的流程中我们忽略了两个重要的过程:发起投票请求与投票请求响应、发送心跳包与心跳包响应,接下来重点介绍这两个过程
3.4 发送投票请求与处理投票请求 节点的状态为Candidate时会向集群内的其他节点发起投票请求(个人认为理解为拉票更好),向对方询问是否愿意选举“我”为Leader,对端节点会根据自己的情况对其投赞成票或拒绝票,如果投拒绝票,还会给出拒绝的原因,具体由voteForQuorumResponses()、handleVote()这两个方法实现,接下来我们分别对这两个方法进行详细分析
3.4.1 voteForQuorumResponses(发起投票请求) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 private List<CompletableFuture<VoteResponse>> voteForQuorumResponses (long term, long ledgerEndTerm, long ledgerEndIndex) throws Exception { List<CompletableFuture<VoteResponse>> responses = new ArrayList <>(); for (String id : memberState.getPeerMap().keySet()) { VoteRequest voteRequest = new VoteRequest (); voteRequest.setGroup(memberState.getGroup()); voteRequest.setLedgerEndIndex(ledgerEndIndex); voteRequest.setLedgerEndTerm(ledgerEndTerm); voteRequest.setLeaderId(memberState.getSelfId()); voteRequest.setTerm(term); voteRequest.setRemoteId(id); voteRequest.setLocalId(memberState.getSelfId()); CompletableFuture<VoteResponse> voteResponse; if (memberState.getSelfId().equals(id)) { voteResponse = handleVote(voteRequest, true ); } else { voteResponse = dLedgerRpcService.vote(voteRequest); } responses.add(voteResponse); } return responses; }
各参数含义如下。
long term:发起投票节点当前维护的投票轮次。
long ledgerEndTerm:发起投票节点当前维护的最大投票轮次。
long ledgerEndIndex:发起投票节点维护的最大日志条目索引。
遍历集群内的所有节点,依次构建投票请求并通过网络异步发送到对端节点,发起投票节点会默认为自己投上一票,投票逻辑被封装在handleVote()方法中。
3.4.2 handleVote(响应投票请求) 因为一个节点可能会收到多个节点的“拉票”请求,存在并发问 题,所以需要引入synchronized机制,锁定状态机memberState对象。接下来我们详细了解其实现逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 if (!memberState.isPeerMember(request.getLeaderId())) { LOGGER.warn("[BUG] [HandleVote] remoteId={} is an unknown member" , request.getLeaderId()); return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNKNOWN_LEADER)); } if (!self && memberState.getSelfId().equals(request.getLeaderId())) { LOGGER.warn("[BUG] [HandleVote] selfId={} but remoteId={}" , memberState.getSelfId(), request.getLeaderId()); return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_UNEXPECTED_LEADER)); }
第一步:先进行一些基础校验。
检查此次拉票请求是否是集群中的一直节点,如果不是则决绝拉票。
如果不是自己给自己拉票,但是拉票节点的ID和自己又一致,则直接拒绝拉票。(异常情况,配置有误,才会走入此分支)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 if (request.getLedgerEndTerm() < memberState.getLedgerEndTerm()) { return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_LEDGER_TERM)); } else if (request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && request.getLedgerEndIndex() < memberState.getLedgerEndIndex()) { return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_SMALL_LEDGER_END_INDEX)); } if (request.getTerm() < memberState.currTerm()) { return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_EXPIRED_VOTE_TERM)); } else if (request.getTerm() == memberState.currTerm()) { if (memberState.currVoteFor() == null ) { } else if (memberState.currVoteFor().equals(request.getLeaderId())) { } else { if (memberState.getLeaderId() != null ) { return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_HAS_LEADER)); } else { return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_ALREADY_VOTED)); } } } else { changeRoleToCandidate(request.getTerm()); needIncreaseTermImmediately = true ; return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_NOT_READY)); } if (request.getTerm() < memberState.getLedgerEndTerm()) { return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.getLedgerEndTerm()).voteResult(VoteResponse.RESULT.REJECT_TERM_SMALL_THAN_LEDGER)); } if (!self && isTakingLeadership() && request.getLedgerEndTerm() == memberState.getLedgerEndTerm() && memberState.getLedgerEndIndex() >= request.getLedgerEndIndex()) { return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.REJECT_TAKING_LEADERSHIP)); } memberState.setCurrVoteFor(request.getLeaderId()); return CompletableFuture.completedFuture(new VoteResponse (request).term(memberState.currTerm()).voteResult(VoteResponse.RESULT.ACCEPT)); }
第二步:根据发起投票节点、当前响应节点维护的投票轮次进行投票仲裁,投票仲裁有如下情况:
如果发起投票节点的 ledgerEndTerm 小于当前节点 ledgerEndTerm,说明发起投票节点的日志复制进度比当前节点低,这种情况是不能成为主节点的,否则会造成数据丢失。所以这种情况会投反对票。
如果发起投票节点和当前节点的 ledgerEndTerm 相等,但是发起投票节点的 ledgerEndIndex 小于当前节点 ledgerEndIndex,这同样说明发起投票节点的日志复制进度比当前节点低,所以拒绝投票。
发起投票节点的投票轮次小于当前节点的投票轮次:投拒绝票,也就是说在Raft协议中,term越大,越有话语权。
起投票节点的投票轮次等于当前节点的投票轮次:说明两者都处在同一个投票轮次中,地位平等,接下来看该节点是否已经投过票。如果该节点已经投过其他节点,则拒绝。
发起投票节点的投票轮次大于当前节点的投票轮次,则拒绝投票请求,并告知对方自己还未准备好投票,会使用发起投票节点的投票轮次立即进入Candidate状态。
如果发起投票节点的投票轮次小于ledgerEndTerm,则拒绝。
如果发起投票节点的ledgerEndTerm等于当前节点的ledgerEndTerm,并且ledgerEndIndex大于等于发起投票节点的ledgerEndIndex,因为这意味着当前节点的日志虽然和发起投票节点在同一轮次,但是当前节点的日志比投票发起者的更新,所以拒绝拉票。
如果以上校验都通过,则将自己的这一票投给这一个投票发起者。
3.5 发送心跳包与处理心跳包 经过几轮投票,其中一个节点会被推举出来成为Leader节点。Leader节点为了维持其领导地位,会定时向从节点发送心跳包,接下来我们重点看心跳包的发送与响应
3.5.1 sendHeartbeats 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private void sendHeartbeats (long term, String leaderId) throws Exception { final AtomicInteger allNum = new AtomicInteger (1 ); final AtomicInteger succNum = new AtomicInteger (1 ); final AtomicInteger notReadyNum = new AtomicInteger (0 ); final AtomicLong maxTerm = new AtomicLong (-1 ); final AtomicBoolean inconsistLeader = new AtomicBoolean (false ); final CountDownLatch beatLatch = new CountDownLatch (1 );
介绍一下局部变量的含义:
allNum:集群内节点个数
succNum:收到成功响应的节点个数
notReadyNum:收到对端没有准备好反馈的节点数量
maxTerm:当前集群中各个节点维护的最大的投票轮次
inconsistLeader:是否存在leader节点不一致的情况
beatLatch:用于等待异步请求结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 for (String id : memberState.getPeerMap().keySet()) { if (memberState.getSelfId().equals(id)) { continue ; } HeartBeatRequest heartBeatRequest = new HeartBeatRequest (); heartBeatRequest.setGroup(memberState.getGroup()); heartBeatRequest.setLocalId(memberState.getSelfId()); heartBeatRequest.setRemoteId(id); heartBeatRequest.setLeaderId(leaderId); heartBeatRequest.setTerm(term); CompletableFuture<HeartBeatResponse> future = dLedgerRpcService.heartBeat(heartBeatRequest); future.whenComplete((HeartBeatResponse x, Throwable ex) -> { try { if (ex != null ) { memberState.getPeersLiveTable().put(id, Boolean.FALSE); throw ex; } switch (DLedgerResponseCode.valueOf(x.getCode())) { case SUCCESS: succNum.incrementAndGet(); break ; case EXPIRED_TERM: maxTerm.set(x.getTerm()); break ; case INCONSISTENT_LEADER: inconsistLeader.compareAndSet(false , true ); break ; case TERM_NOT_READY: notReadyNum.incrementAndGet(); break ; default : break ; } if (x.getCode() == DLedgerResponseCode.NETWORK_ERROR.getCode()) memberState.getPeersLiveTable().put(id, Boolean.FALSE); else memberState.getPeersLiveTable().put(id, Boolean.TRUE); if (memberState.isQuorum(succNum.get()) || memberState.isQuorum(succNum.get() + notReadyNum.get())) { beatLatch.countDown(); } } catch (Throwable t) { LOGGER.error("heartbeat response failed" , t); } finally { allNum.incrementAndGet(); if (allNum.get() == memberState.peerSize()) { beatLatch.countDown(); } } }); }
遍历集群中所有的节点,构建心跳数据包并异步向集群内的从节点发送心跳包,心跳包中主要包含Raft复制组名、当前节点ID、远程节点ID、当前集群中的leaderId、当前节点维护的投票轮次。
当收到一个节点的响应结果后触发回调函数,统计响应结果,先介绍一下对端节点的返回结果。
SUCCESS:心跳包成功响应。
EXPIRED_TERM:节点的投票轮次小于从节点的投票轮次。
INCONSISTENT_LEADER:从节点已经有了新的主节点。
TERM_NOT_READY:从节点未准备好。
根据错误码,判断节点是否存活。
如果收到SUCCESS的从节点数量超过集群节点的半数,或者收到集群内所有节点的响应结果后调用CountDownLatch的countDown()方法从而唤醒了主线程,则继续执行后续流程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 if (maxTerm.get() > term) { LOGGER.warn("[{}] currentTerm{} is not the biggest={}, deal with it" , memberState.getSelfId(), term, maxTerm.get()); changeRoleToCandidate(maxTerm.get()); return ; } if (memberState.isQuorum(succNum.get())) { lastSuccHeartBeatTime = System.currentTimeMillis(); } else { LOGGER.info("[{}] Parse heartbeat responses in cost={} term={} allNum={} succNum={} notReadyNum={} inconsistLeader={} maxTerm={} peerSize={} lastSuccHeartBeatTime={}" , memberState.getSelfId(), DLedgerUtils.elapsed(startHeartbeatTimeMs), term, allNum.get(), succNum.get(), notReadyNum.get(), inconsistLeader.get(), maxTerm.get(), memberState.peerSize(), new Timestamp (lastSuccHeartBeatTime)); if (memberState.isQuorum(succNum.get() + notReadyNum.get())) { lastSendHeartBeatTime = -1 ; } else if (inconsistLeader.get()) { changeRoleToCandidate(term); } else if (DLedgerUtils.elapsed(lastSuccHeartBeatTime) > (long ) maxHeartBeatLeak * heartBeatTimeIntervalMs) { changeRoleToCandidate(term); } }
心跳响应结果有下列情况:
如果从节点的选举周期大于当前节点,则立即将当前节点的状态更改为Candidate
如果当前Leader节点收到超过集群半数节点的认可(SUCCESS),表示集群状态正常,则正常按照心跳包间隔发送心跳包。
如果当前Leader节点收到SUCCESS的响应数加上未准备投票的节点数超过集群节点的半数,则立即发送心跳包。
如果leader变成了其他节点,则将当前节点状态更改为Candidate。
最近成功发送心跳的时间戳超过最大允许的间隔时间,则将当前节点状态更改为Candidate。
3.5.2 handleHeartBeat 该方法是从节点在收到主节点的心跳包后的响应逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public CompletableFuture<HeartBeatResponse> handleHeartBeat (HeartBeatRequest request) throws Exception { if (!memberState.isPeerMember(request.getLeaderId())) { LOGGER.warn("[BUG] [HandleHeartBeat] remoteId={} is an unknown member" , request.getLeaderId()); return CompletableFuture.completedFuture(new HeartBeatResponse ().term(memberState.currTerm()).code(DLedgerResponseCode.UNKNOWN_MEMBER.getCode())); } if (memberState.getSelfId().equals(request.getLeaderId())) { LOGGER.warn("[BUG] [HandleHeartBeat] selfId={} but remoteId={}" , memberState.getSelfId(), request.getLeaderId()); return CompletableFuture.completedFuture(new HeartBeatResponse ().term(memberState.currTerm()).code(DLedgerResponseCode.UNEXPECTED_MEMBER.getCode())); }
这一部分代码做了一些基础的校验,校验收到的这个请求是否是当前集群中的节点。
1 2 3 4 5 6 7 8 9 10 11 if (request.getTerm() < memberState.currTerm()) { return CompletableFuture.completedFuture(new HeartBeatResponse ().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode())); } else if (request.getTerm() == memberState.currTerm()) { if (request.getLeaderId().equals(memberState.getLeaderId())) { lastLeaderHeartBeatTime = System.currentTimeMillis(); return CompletableFuture.completedFuture(new HeartBeatResponse ()); } }
第一步:如果发送心跳包的节点(Leader节点)的投票轮次小于从节点的投票轮次,返回EXPIRED_TERM,告知对方它的投票轮次已经过期,需要重新进入选举。如果Leader节点的投票轮次与当前从节点的投票轮次相同,并且发送心跳包的节点(Leader节点)是当前从节点的主节点,则返回成功。这一步中的校验并没有加锁,目的是为了提高并发性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 synchronized (memberState) { if (request.getTerm() < memberState.currTerm()) { return CompletableFuture.completedFuture(new HeartBeatResponse ().term(memberState.currTerm()).code(DLedgerResponseCode.EXPIRED_TERM.getCode())); } else if (request.getTerm() == memberState.currTerm()) { if (memberState.getLeaderId() == null ) { changeRoleToFollower(request.getTerm(), request.getLeaderId()); return CompletableFuture.completedFuture(new HeartBeatResponse ()); } else if (request.getLeaderId().equals(memberState.getLeaderId())) { lastLeaderHeartBeatTime = System.currentTimeMillis(); return CompletableFuture.completedFuture(new HeartBeatResponse ()); } else { LOGGER.error("[{}][BUG] currTerm {} has leader {}, but received leader {}" , memberState.getSelfId(), memberState.currTerm(), memberState.getLeaderId(), request.getLeaderId()); return CompletableFuture.completedFuture(new HeartBeatResponse ().code(DLedgerResponseCode.INCONSISTENT_LEADER.getCode())); } } else { changeRoleToCandidate(request.getTerm()); needIncreaseTermImmediately = true ; return CompletableFuture.completedFuture(new HeartBeatResponse ().code(DLedgerResponseCode.TERM_NOT_READY.getCode())); } }
第二步:通常情况下第一步将直接返回,本步骤主要用于处理异常情况,需要加锁以确保线程安全,核心处理逻辑如下:
如果发送心跳包的节点(Leader节点)的投票轮次小于当前从节点的投票轮次,返回EXPIRED_TERM,告知对方它的投票轮次已经过期,需要重新进入选举,对端节点将会立即变为Candidate状态。
如果发送心跳包的节点的投票轮次等于当前从节点的投票轮次,需要根据当前从节点维护的leaderId来继续判断下列情况:
当前节点还不知道谁是Leader时,收到心跳包,则将leader节点设置为该心跳发送的节点
如果Leader发出的心跳任期和自己的任期相同,则更新lastLeaderHeartBeatTime,表示收到心跳包,并更新lastLeaderHeartBeatTime。
如果当前从节点的维护的主节点ID与发送心跳包的节点ID不同, 说明集群中存在另外一个Leader节点,则返回INCONSISTENT_LEADER,对端节点将进入Candidate状态
如果心跳中的任期大于当前节点的任期,则将自己的状态更改为Candidate,并进入新的任期选举状态,并返回TERM_NOT_READY,这样主节点可能会立即再发一次心跳。
3.6 整体流程 至此,我们从源码的角度分析了DLedger是如何实现Raft选主功能的,以及如何在一个节点发生宕机后进行主从切换。
四. 总结 本文深入剖析了DLedger,一个基于Raft协议实现的Java类库,它在RocketMQ 4.5版本中被引入,用以解决分布式系统中的高可用性和数据一致性问题。DLedger的核心功能之一是Leader选举,该过程确保了在任何节点故障的情况下,系统能够自动且迅速地选出新的Leader节点,以维持服务的连续性和稳定性。
DLedger的Leader选举机制遵循Raft协议,包含以下几个关键步骤:
初始化与状态转换 :每个节点初始状态为Follower。在一定时间后,如果未收到Leader的心跳,Follower将转换为Candidate状态,并发起投票。随机计时器 :为避免同时发起选举,每个节点的选举超时时间是随机的。投票过程 :Candidate节点向集群中的其他节点发送投票请求,并根据收到的响应来确定是否赢得选举。日志复制 :一旦Candidate赢得选举,成为Leader,它将负责处理所有写请求,并将日志条目复制到所有从节点。心跳机制 :Leader定期向所有Follower发送心跳包,以维持其领导地位,并确保Follower不会转换为Candidate。角色变更处理 :在选举过程中,节点可能需要从Follower转换为Candidate,或从Candidate转换为Leader,DLedger通过内部状态机管理这些转换。
本文参考至:《RocketMQ技术内幕 第二版》